利用 kong 进行流量负载均衡处理
这篇笔记聚焦用 Kong Upstream 为 Kubernetes 中的后端副本做流量分发,场景是 3 个 Pod 暴露在 10.42.0.20 到 10.42.0.22,并通过 Target 与 Service 组合交给 Kong 选择实际后端。内容先区分 Round Robin、Least Connections 与 Consistent Hashing:无状态标准 API 适合轮询,耗时较长的 RAG 向量计算更适合最小连接数,而带本地缓存、用户 Session 或上下文依赖的服务则需要哈希分流来保持请求落点稳定。配置层面强调 Upstream 模式与直连模式的差异,Service Host 指向 upstream 名称后,Service Port 即使写 80 也不会决定最终端口,Kong 会根据上游 Target 中的地址与端口转发到具体的 10.42.0.x:8006。文章还用取余哈希和一致性哈希对比解释扩缩容影响:简单取模在节点数量变化时会导致大量请求重新分布,而 Kong 的一致性哈希通过环形空间顺时针查找,只让新增或减少节点附近的一小段流量发生漂移。对于依赖缓存命中率的 RAG 服务,这种机制能降低扩容、缩容或 Pod 变更时的缓存失效范围,避免瞬时流量冲击。最后对 Target 的 weight 做了关键澄清:在一致性哈希下它更像虚拟节点数量,权重越高,在哈希环上的“分身”和覆盖范围越多,从而获得更大比例的请求,适合需要按 Pod 能力差异分配流量的后端服务。
| 策略 | 场景(最适合做什么) | 优点 |
|---|---|---|
| Round Robin (轮询) | 标准 API、无状态服务。比如查天气、查公共信息。 | 绝对公平,请求被均匀地洒在每个 Pod 上。 |
| Least Connections (最小连接数) | 耗时长的任务。比如 RAG 向量计算。 | 谁手里的活少,就把新活给谁,避免某个 Pod 被慢请求堵死。 |
| Consistent Hashing (哈希分流) | 有缓存、有上下文的服务。比如你的 RAG 缓存、用户 Session。 | 定向分流。保证同一个用户的请求总能找到同一个 Pod,利用好内存里的缓存。 |
设置upstreams与分发#
后端使用了 k8s 部署了 3 个副本进行处理。
三个内网地址分别是10.42.0.20-10.42.0.22
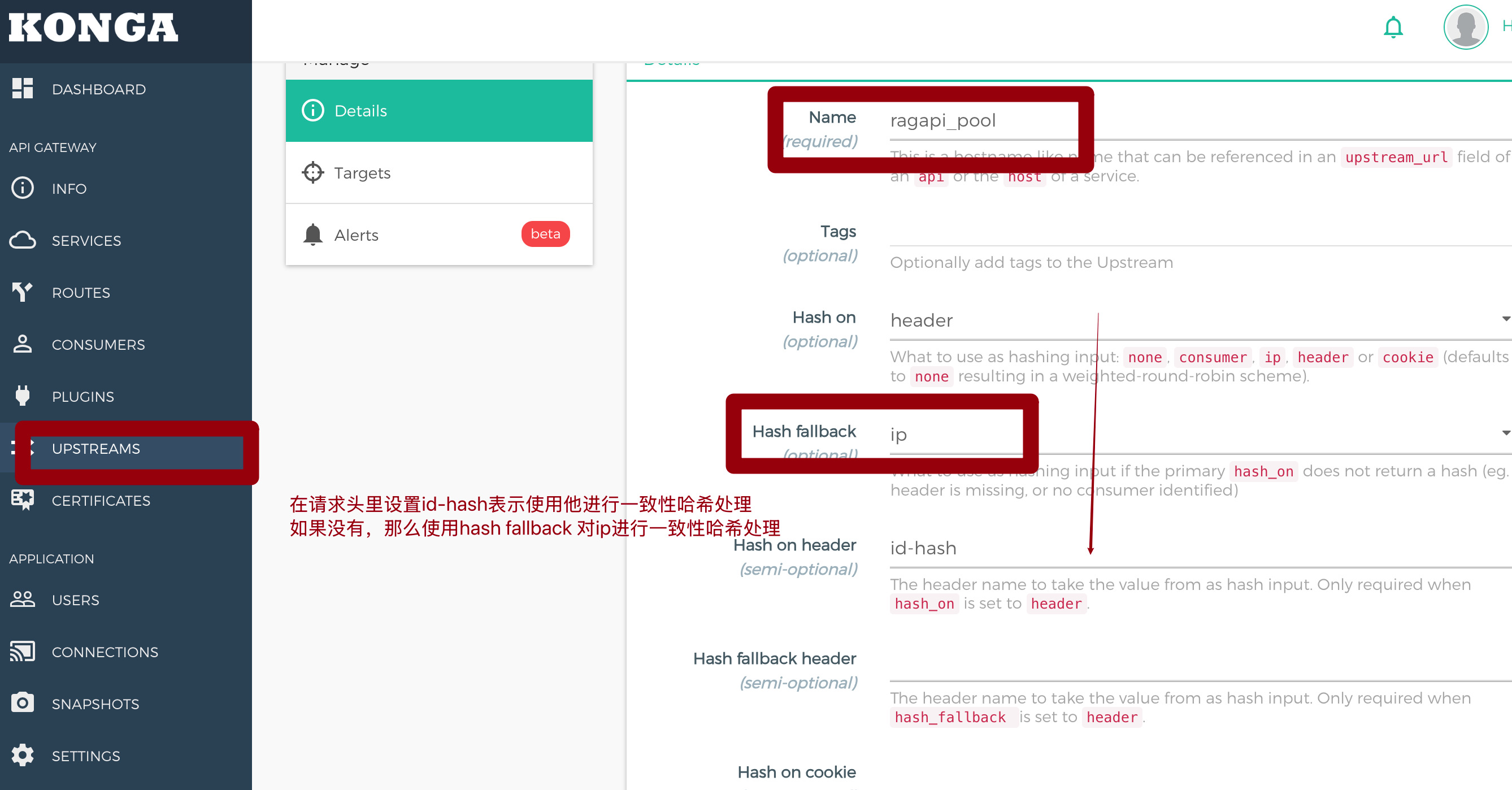
设置 target:

设置 services:

在 Upstream 模式下,端口 80 会被“无视”掉。
| 配置方式 | Service Host | Service Port | Kong 最终转发到哪里? |
|---|---|---|---|
| 直连模式 | 10.42.0.20 | 8006 | 10.42.0.20:8006 (死板) |
| Upstream 模式 | ragapi_pool | 80 (随意) | 根据哈希算法 选出 10.42.0.x:8006 (灵活) |
一致性哈希#
| 特性 | 取余哈希 (Modulo) | 一致性哈希 (Kong) |
|---|---|---|
| 计算方式 | 直接取模 | 环形空间顺时针查找 |
| 扩展性 | 极差(扩容导致全线缓存失效) | 极好(仅局部受影响) |
| 权重支持 | 较难直接支持 | 通过虚拟节点数量完美支持 |
| 适用场景 | 节点永远固定不变的场景 | 云原生、容器化、经常扩缩容的场景 |
1. 取余哈希(Modulo Hashing):传统的“简单粗暴”
这是最直观的逻辑。假设你有 N 个 Pod。
• 算法:hash(key) mod N
• 缺点(致命伤):容错性极差。
◦ 比如你有 3 个 Pod,请求 123 会打到第 123 mod 3 = 0 号 Pod。
◦ 如果你新增一个 Pod 变成 4 个,请求 123 会打到第 123 mod 4 = 3 号 Pod。
◦ 后果:当你增加或减少哪怕一个 Pod,几乎所有的请求落点都会发生改变。在场景下,这意味着几乎所有 Worker 的本地缓存都会失效,造成瞬间的流量冲击。
Kong 默认(在开启 Hash 时)采用的是一致性哈希。它把整个哈希值空间想象成一个 0 到 2^{32}-1 的圆环。
原理拆解:
- 节点映射:Kong 将你的 Target(Pod IP)通过哈希函数映射到这个环上的某个点。
- 请求映射:当请求带着
id-hash进来时,同样计算哈希值,落在环上的某个位置。 - 寻找后端:请求在环上顺时针行走,遇到的第一个节点就是它要访问的 Pod。 为什么它能解决你的困惑? • 增加节点时:如果你增加第 4 个 Pod,它只会在圆环上占据一小段弧度。只有原本落在这一段弧度上的请求会漂移到新 Pod,其他请求在环上顺时针遇到的第一个节点依然是原来的那个。 • 稳定性:它将缓存失效的范围控制在最小(只有 1/N的流量受影响)。
Target 里的 Weight(权重)到底是什么?
在一致性哈希的语境下,weight 并不是简单的“比例”,而是 “虚拟节点(Virtual Nodes / Slots)”的数量。
如果 3 个 Pod 只是简单地在圆环上打 3 个点,由于哈希的随机性,可能导致圆环被分割得非常不均匀(比如 Pod-1 占了 70% 的面积)。
Weight 的作用:
- 增加覆盖面:当你给一个 Target 设置
weight: 100时,Kong 实际上会在圆环上生成 100 个“分身”(虚拟节点),散落在圆环的各个角落。 - 实现负载分配:
- 如果 Pod-1 的
weight是 100,Pod-2 的weight是 200。 - Pod-2 就会在圆环上拥有 2 倍于 Pod-1 的“领地”。
- 结果:Pod-2 拿到的流量理论上就是 Pod-1 的两倍。
- 如果 Pod-1 的
评论
还没有评论,来发第一个吧