LangGraph-概览
这是一份面向复杂 AI Agent 设计与面试准备的 LangGraph 导读,核心对象是其状态驱动的有向图工作流模型,以及它相对 LangChain 线性 Chain 在动态分支、并行执行和显式状态管理上的差异。内容围绕 State、Reducer、Node、Edge、Conditional Edge 等关键概念展开,说明 State 如何承担节点通信和多会话隔离,Reducer 如何处理并发写入时的消息追加、列表合并或覆盖策略。文章还梳理了条件路由、thread_id 与 Checkpointer、Fan-out/Fan-in、Early Exit、Fallback 等常见设计模式,用客服 Agent 场景串联商品查询、订单查询、投诉处理、多用户并发和 SLA 保证的系统设计思路。可靠性部分强调 Node 应保持单一职责、幂等、异步优先并具备错误处理,路由函数也应只依赖 State,避免随机数、时间或全局变量造成重试和回放不一致。可观测性则以 Langfuse 为例,覆盖 Trace、Token 成本、延迟、提示词版本和 A/B 测试等运维视角。适合正在从简单 LLM 调用转向可生产化 Agent 编排的后端开发、AI 应用开发者和准备相关系统设计面试的读者。
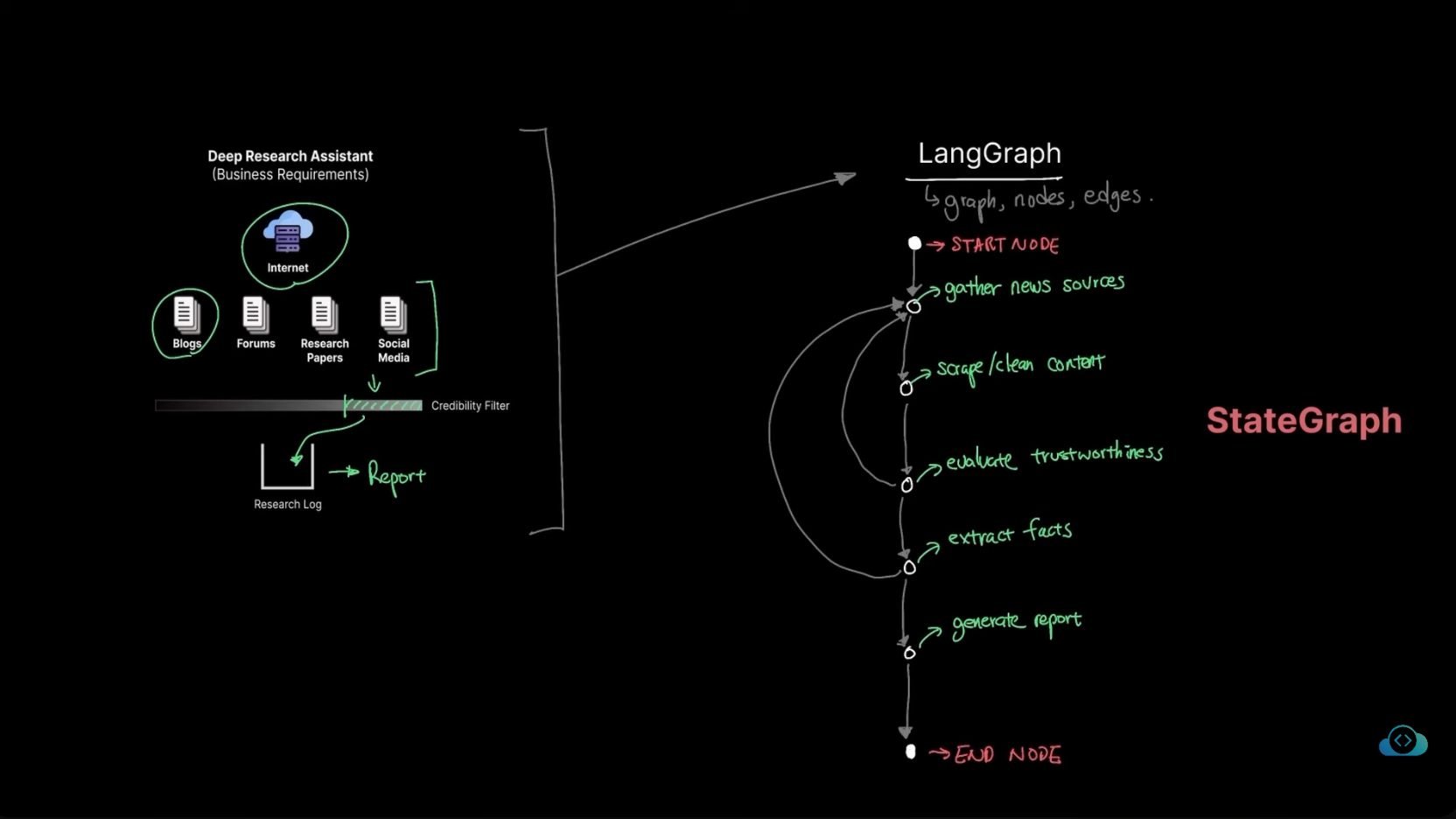
LangGraph 完全指南#
核心概念速览#
LangGraph 是一个状态驱动的有向图工作流框架,用于构建复杂的 AI Agent 系统。相比简单的 Chain,它提供了:
- 图模型设计 - 支持分支、并行、条件路由
- 状态管理 - 统一的 State 对象在节点间流转
- 并发隔离 - 通过 thread_id 实现多用户隔离
- 可观测性 - 完整的 Trace、日志、指标
- 容错机制 - Checkpointer、Fallback、Early Exit
面试高频问题#
Q1: LangGraph 与 LangChain 的区别是什么?#
核心差异:
| 维度 | LangChain | LangGraph |
|---|---|---|
| 结构 | 线性 Chain | 有向图 Graph |
| 流程 | 固定顺序 | 动态分支 |
| 状态 | 隐式传递 | 显式 State 对象 |
| 路由 | 简单条件 | 复杂条件路由 |
| 并发 | 有限支持 | 原生支持 |
| 适用场景 | 简单流程 | 复杂 Agent |
面试答法:
"LangChain 是链式调用,适合简单的 prompt → LLM → 输出流程。但当需要处理复杂的业务逻辑、多分支决策、并发处理时,LangChain 就显得力不从心了。
LangGraph 引入了图的概念,每个节点是一个处理步骤,节点之间通过边连接。关键是支持条件路由——根据当前状态动态决定下一步走哪条路,这对于 Agent 系统至关重要。
比如一个客服 Agent,需要根据用户意图分别走商品查询、订单查询或投诉处理的不同分支,这种场景 LangGraph 就很适合。"
Q2: State 和 Reducer 的作用是什么?#
State 的核心作用:
- 节点间通信 - 所有节点通过读写同一个 State 对象交互
- 状态隔离 - 结合 thread_id,实现多用户并发隔离
- 类型安全 - 使用 TypedDict 确保数据结构一致
- Reducer 合并 - 当多个节点并发更新同一字段时,Reducer 决定如何合并
Reducer 的三种常见模式:
1. add_messages - 消息追加(不覆盖)
用途:聊天历史、对话记录
2. 自定义 Reducer - 列表合并、去重等
用途:检索结果、候选项汇聚
3. 无 Reducer - 后写覆盖
用途:单一字段更新、不需要合并
面试答法:
"State 是 LangGraph 的核心数据结构,定义了图执行过程中流转的信息。每个节点都是一个处理函数,接收 State,返回更新后的 State。
关键是 Reducer 的概念。当多个节点并发执行时,可能同时更新同一个字段。比如多个检索节点同时写入 search_results,如果没有 Reducer,后面的写入会覆盖前面的。
Reducer 就是一个合并函数,定义了如何处理并发更新。比如 add_messages 会追加消息而不是覆盖,自定义 Reducer 可以实现列表合并、去重等逻辑。
另一个重要的是通过 thread_id 实现状态隔离。每个用户/会话有独立的 State 副本,不会互相影响。"
Q3: Conditional Edge 如何实现动态路由?#
三层路由设计:
第一层:固定路由(add_edge)
node_a → node_b(总是这样走)
第二层:条件路由(add_conditional_edges)
根据 state 的内容动态决定下一步
第三层:复杂路由(多条件组合)
多个条件组合判断,支持提前结束
路由函数的关键要素:
- 幂等性 - 同样的 State 应该返回同样的结果
- 完整性 - 处理所有可能的情况,不能有无法路由的 State
- 清晰性 - 路由逻辑简洁,复杂逻辑放在节点内部
面试答法:
"Conditional Edge 是 LangGraph 相比 Chain 最强大的地方。它允许根据当前 State 的内容动态决定下一个节点。
实现方式是定义一个路由函数,接收 State,返回下一个节点的名称。比如:
- 如果用户问题包含敏感词,路由到错误处理节点
- 如果识别出是商品查询,路由到商品检索节点
- 如果检索结果为空,路由到兜底方案节点
这样就能实现复杂的业务逻辑分支。关键是路由函数要幂等——同样的 State 应该返回同样的结果,这样才能保证系统的可预测性。"
Q4: 如何实现多用户并发隔离?#
隔离的三个层次:
第一层:thread_id 隔离
每个用户/会话有唯一的 thread_id
第二层:Checkpointer 持久化
每个 thread_id 有独立的 State 快照
第三层:拓扑隔离
并行分支写入不同的 State 字段,避免冲突
thread_id 的设计:
基础隔离:
user_{user_id}
room_{room_id}
多层隔离:
{room_id}:{user_id}:{session_id}
面试答法:
"多用户隔离的核心是 thread_id。每个用户/会话有唯一的 thread_id,LangGraph 会根据 thread_id 为每个用户维护独立的 State 副本。
Checkpointer 是持久化层,它在每个执行步骤保存 State 的快照。这样即使系统崩溃,也能从上次中断的地方继续执行。
常见的 Checkpointer 有三种:
- MemorySaver:内存存储,简单快速,但重启后丢失
- PostgresSaver:数据库存储,支持分布式,生产环境推荐
- SqliteSaver:SQLite 存储,轻量级,适合单机
另外,通过拓扑隔离也能避免冲突。比如多个并行节点各自写入不同的 State 字段,就不需要 Reducer,因为不存在并发写入同一字段的情况。"
Q5: 如何处理长流程中的超时和 SLA 保证?#
四层防护机制:
第一层:节点级超时
每个节点设置 timeout,防止单个节点卡住
第二层:关键路径切分
将流程分为【关键前置】和【异步生成】两部分
第三层:Early Exit 机制
关键路径完成后立即返回,不等待异步部分
第四层:外层 Event 监听
使用 asyncio.wait_for 为整个流程设置超时
实现思路:
用户请求
↓
【关键前置路径】(必须完成)
- 预处理、验证、路由、检索等
- 设置 25 秒超时
↓
返回 can_return_event 信号
↓
立即向用户返回响应
↓
【异步生成路径】(后台执行)
- 文本生成、流式推送等
- 不阻塞用户请求
面试答法:
"这是一个很实际的问题。在实时系统中,必须保证接口的 SLA,不能因为某个内部节点卡住就让用户一直等待。
我们的做法是将流程分为两部分:
-
关键前置路径 - 包括预处理、验证、意图识别、检索等必须完成的步骤。这部分设置 25 秒的超时。
-
异步生成路径 - 包括文本生成、流式推送等耗时操作。这部分在后台执行,不阻塞用户请求。
关键是在关键路径完成后立即返回 can_return_event 信号,系统就向用户返回响应。异步部分继续在后台执行,通过 Redis 或其他方式推送结果。
这样既保证了接口的 SLA,又实现了大模型的流式异步推流。"
Q6: 如何设计 Node 才能保证系统的可靠性?#
Node 设计的五个原则:
1. 单一职责
每个 Node 只做一件事,职责清晰
2. 幂等性
同样的输入应该产生同样的输出
3. 错误处理
不要让一个 Node 的失败导致整个图崩溃
4. 异步优先
I/O 操作使用 async,充分利用并发
5. 可观测
记录日志、上报指标、便于调试
常见的 Node 类型:
1. 预处理 Node
- 清理输入、基础验证
- 例:去除空格、检查长度
2. 过滤 Node
- 检测敏感词、垃圾内容
- 例:黑名单检查、内容审核
3. 识别 Node
- 调用 LLM 进行分类、提取
- 例:意图识别、实体提取
4. 检索 Node
- 从数据库、向量库查询
- 例:商品检索、知识库查询
5. 生成 Node
- 调用 LLM 生成最终结果
- 例:答案生成、文案生成
面试答法:
"Node 的设计直接影响系统的可靠性。我遵循以下原则:
首先是单一职责。每个 Node 只做一件事,比如预处理 Node 只负责清理输入,不涉及业务逻辑。这样代码清晰,易于测试和维护。
其次是幂等性。同样的输入应该产生同样的输出。这很重要,因为 LangGraph 可能会重试某个 Node,如果不幂等就会产生不一致的结果。
第三是错误处理。每个 Node 都要处理可能的异常,不能让一个 Node 的失败导致整个图崩溃。比如检索失败时,返回空结果而不是抛异常。
第四是异步优先。对于 I/O 操作(网络请求、数据库查询等),使用 async 函数,这样可以充分利用并发,提高吞吐量。
最后是可观测。记录详细的日志、上报关键指标,这样出问题时能快速定位原因。"
Q7: 如何在 LangGraph 中实现 Fan-out / Fan-in 并行模式?#
两种并行方式:
方式一:多 Edge Fan-out(推荐)
从同一个节点添加多条 Edge
graph.add_edge("init", "task_a")
graph.add_edge("init", "task_b")
graph.add_edge("init", "task_c")
→ task_a、task_b、task_c 自动并行执行
方式二:Send 动态分支
在节点内部使用 Send 发送多个任务
→ 适合动态分支数量的场景
Fan-in 屏障同步:
多条 Edge 汇聚到同一个节点时
LangGraph 自动等待所有上游分支完成
才执行该节点
这实现了隐式的屏障同步
面试答法:
"Fan-out / Fan-in 是并行处理的常见模式。
Fan-out 的实现很简单——从同一个节点添加多条 Edge。LangGraph 会自动并行执行所有下游节点。比如初始化节点完成后,可以同时执行风险检测、意图识别、数据预处理等多个任务。
关键是这些并行任务要写入不同的 State 字段,这样就不存在冲突。如果需要写入同一字段,就要用 Reducer 来合并。
Fan-in 是多条 Edge 汇聚到同一个节点。LangGraph 会自动等待所有上游分支完成才执行该节点,这实现了隐式的屏障同步。比如多个检索任务完成后,再执行答案生成节点。
这种设计能充分利用并发,提高系统吞吐量。"
Q8: 如何使用 Langfuse 进行可观测性?#
Langfuse 的三个核心功能:
1. Trace 追踪
记录每个 Node 的执行过程
- 输入、输出、耗时
- 调用链路、错误信息
2. 指标监控
- Token 使用量
- 成本统计
- 延迟分布
3. 提示词管理
- 版本控制
- A/B 测试
- 性能对比
集成方式:
1. 在 LangGraph 中集成 Langfuse
- 自动记录每个 Node 的执行
- 记录 LLM 调用
2. 自定义 Trace
- 在关键节点添加 trace 点
- 记录业务指标
3. 分析和优化
- 查看执行链路
- 分析性能瓶颈
- 对比不同版本
面试答法:
"Langfuse 是 LangGraph 生态中很重要的可观测性工具。它能帮助我们理解 Agent 的执行过程,发现性能瓶颈,优化系统。
主要功能有三个:
-
Trace 追踪 - 记录每个 Node 的执行过程,包括输入、输出、耗时、错误等。这样能清楚地看到整个执行链路,快速定位问题。
-
指标监控 - 统计 Token 使用量、成本、延迟等关键指标。这对于成本控制和性能优化很重要。
-
提示词管理 - 对提示词进行版本控制,支持 A/B 测试。这样能科学地优化提示词,而不是凭感觉。
在实际项目中,我们会在关键节点添加 Trace 点,记录业务指标。然后通过 Langfuse 的仪表板分析数据,找出优化方向。"
系统设计题#
题目:设计一个客服 Agent 系统#
需求:
- 支持多种问题类型(商品查询、订单查询、投诉处理)
- 支持多用户并发
- 需要保证 SLA(2 秒内返回)
- 需要完整的可观测性
设计思路:
第一步:定义 State
- 用户问题、意图、检索结果、最终回答
- 使用 thread_id 隔离不同用户
第二步:设计 Node
- 预处理 Node:清理输入
- 意图识别 Node:分类问题类型
- 检索 Node:根据意图查询不同数据源
- 生成 Node:生成最终回答
第三步:设计路由
- 根据意图路由到不同的检索逻辑
- 如果检索失败,路由到兜底方案
第四步:处理 SLA
- 关键路径(预处理 + 意图识别 + 检索)设置 1.5 秒超时
- 生成部分异步执行,不阻塞用户请求
第五步:可观测性
- 使用 Langfuse 记录每个 Node 的执行
- 监控关键指标:延迟、成功率、成本
面试答法框架:
"我会从以下几个方面设计这个系统:
架构设计:
- 使用 LangGraph 构建有向图,每个节点代表一个处理步骤
- 通过 Conditional Edge 实现动态路由
并发隔离:
- 使用 thread_id 为每个用户维护独立的 State
- 使用 PostgreSQL Checkpointer 持久化状态
性能优化:
- 将流程分为关键路径和异步路径
- 关键路径完成后立即返回,异步部分后台执行
- 使用 asyncio 实现并发
可靠性:
- 每个 Node 都有错误处理和重试机制
- 使用 Fallback 处理异常情况
- 设置合理的超时时间
可观测性:
- 集成 Langfuse 记录完整的执行链路
- 监控关键指标:延迟、成功率、成本
- 定期分析数据,优化系统"
常见陷阱#
陷阱 1:State 设计过于复杂#
❌ 错误做法:
把所有信息都放进 State
- 完整的用户信息
- 所有历史消息
- 所有检索结果
✅ 正确做法:
只保留当前链路需要的信息
- 用户 ID(不是完整用户信息)
- 最近的消息(不是所有历史)
- 关键检索结果(不是所有结果)
面试答法: "State 应该精简,只保留当前链路需要的信息。这样可以减少序列化开销,提高性能。如果把所有信息都放进 State,会导致每次执行都要序列化大量数据,严重影响性能。"
陷阱 2:路由函数不幂等#
❌ 错误做法:
路由函数依赖外部状态
- 调用随机函数
- 依赖当前时间
- 依赖全局变量
✅ 正确做法:
路由函数只依赖 State
- 同样的 State 返回同样的结果
- 支持重试和回放
面试答法: "路由函数必须幂等。这很重要,因为 LangGraph 可能会重试某个节点,如果路由函数不幂等,就会产生不一致的结果。比如路由函数不能调用随机函数或依赖当前时间,只能依赖 State 的内容。"
陷阱 3:忽视错误处理#
❌ 错误做法:
假设所有操作都成功
- 不处理网络错误
- 不处理数据库错误
- 不处理 LLM 调用失败
✅ 正确做法:
每个 Node 都有完整的错误处理
- Try-catch 捕获异常
- 返回默认值或兜底方案
- 记录错误日志
面试答法: "在分布式系统中,故障是常态。每个 Node 都要有完整的错误处理,不能假设所有操作都成功。比如检索失败时,应该返回空结果而不是抛异常,这样后续的生成 Node 可以使用兜底方案。"
总结#
LangGraph 的核心价值:
- 图模型 - 支持复杂的分支和并行
- 状态管理 - 统一的 State 对象,支持并发隔离
- 动态路由 - 根据状态动态决定下一步
- 可观测性 - 完整的 Trace 和指标
- 容错机制 - Checkpointer、Fallback、Early Exit
面试准备建议:
- 理解核心概念 - State、Node、Edge、Conditional Edge
- 掌握设计模式 - Fan-out/Fan-in、Early Exit、Fallback
- 学会系统设计 - 如何设计一个完整的 Agent 系统
- 关注可靠性 - 错误处理、超时、SLA 保证
- 了解可观测性 - Langfuse、日志、指标
常见问题速查表:
| 问题 | 关键点 |
|---|---|
| 与 LangChain 的区别 | 图 vs 链、动态路由、并发支持 |
| State 和 Reducer | 节点通信、并发合并、类型安全 |
| 条件路由 | 幂等性、完整性、清晰性 |
| 多用户隔离 | thread_id、Checkpointer、拓扑隔离 |
| 超时和 SLA | 关键路径切分、Early Exit、外层监听 |
| Node 设计 | 单一职责、幂等性、错误处理、异步优先 |
| 并行处理 | 多 Edge Fan-out、Fan-in 屏障同步 |
| 可观测性 | Langfuse、Trace、指标、提示词管理 |
评论
还没有评论,来发第一个吧