LLM 应用评估体系-1
这是一份面向 LLM 应用质量工程的评估体系笔记,核心关注如何把模型输出从上线后的偶发检查,转为可监控、可比较、可归因的持续改进闭环。正文先建立多维指标框架,将准确性、相关性、完整性、格式合规和语气适配按权重拆分,并补充 RAGAS 中 Context Precision、Context Recall、Faithfulness、Answer Relevance 等检索与生成指标的目标值和评估方法。随后围绕提示词优化给出 A/B 测试流程、样本量计算思路、多臂老虎机分流策略,以及 Dev、Canary、Prod 的版本管理方式。评估器部分重点说明 LLM-as-a-Judge 的结构化提示词、与人工标注的一致性校验、常见偏差规避,以及评估延迟、成本、覆盖率等运行监控。文章还覆盖人工标注工作流、Kappa 等一致性指标、分歧处理、数据集版本与训练/验证/测试集划分,并用失败分类和归因模板连接到后续优化。最后以 Langfuse 为例串起 Trace 记录、评分、Annotation Queue、数据集管理、Dashboard 监控和提示词版本对比,适合正在搭建 RAG、智能客服或其他生产级 LLM 应用评估闭环的开发与平台团队参考。
LLM 应用评估体系完全指南#
a
核心理念#
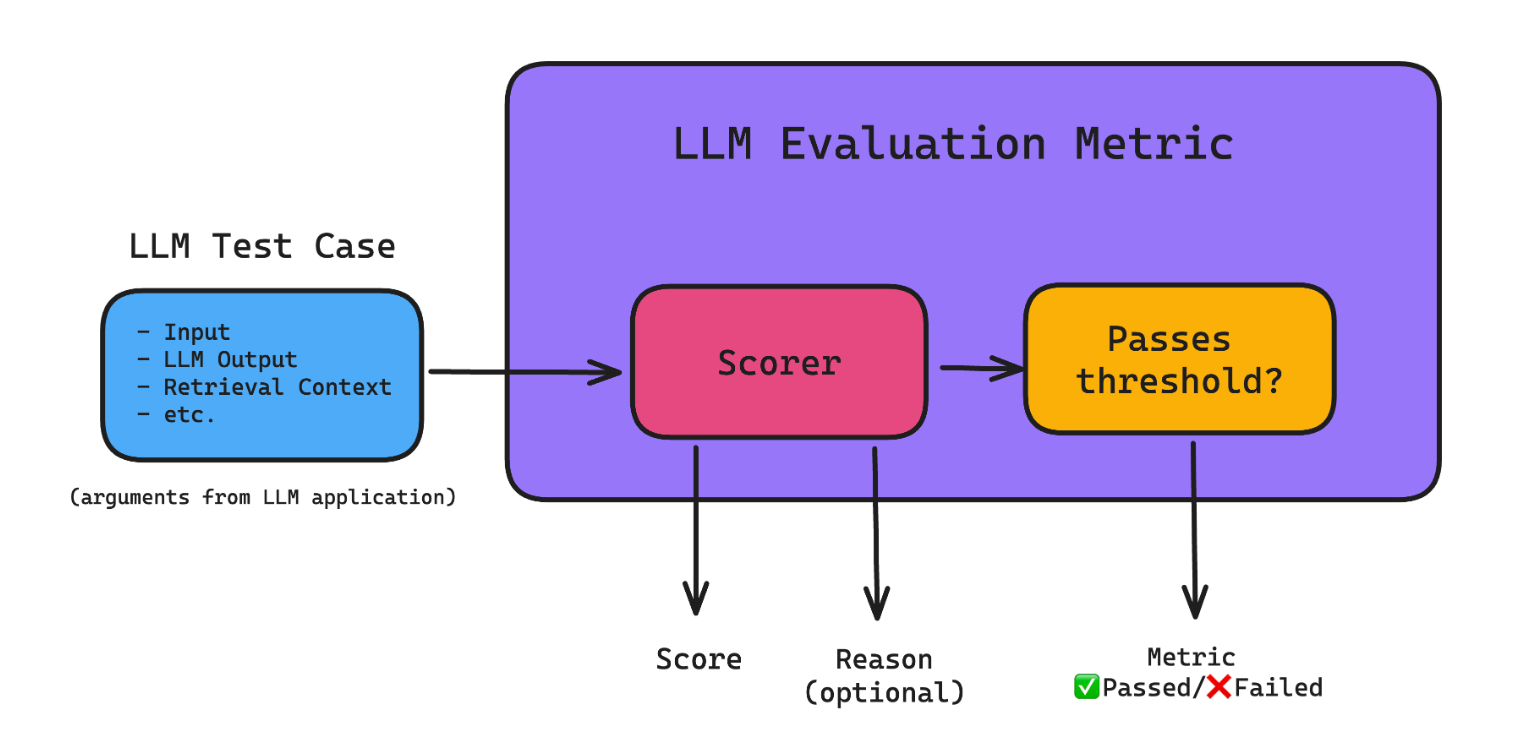
评估体系是 LLM 应用从"能用"到"好用"的关键。它不仅是事后的质量检查,更是持续改进的闭环反馈机制。
开发 → 部署 → 监控 → 评估 → 改进 → 开发
↑_________↓
评估体系
第一部分:多维度评估指标体系#
1.1 评估维度设计#
一个完整的评估体系应该包含以下维度:
| 维度 | 定义 | 评估方法 | 权重 |
|---|---|---|---|
| 准确性 | 输出是否符合事实、是否存在幻觉 | LLM 裁判 + 人工审核 | 40% |
| 相关性 | 输出是否回答了用户的问题 | 语义相似度 + 人工评分 | 25% |
| 完整性 | 输出是否包含了必要的信息 | 检查清单 + 人工评分 | 20% |
| 格式合规 | 输出是否符合预期格式 | 自动检查 | 10% |
| 语气适配 | 输出的语气是否合适 | LLM 裁判 + 人工评分 | 5% |
1.2 评分标准设计#
五级评分体系:
5 分 - 优秀
✓ 完全准确、完整、相关
✓ 格式完美、语气恰当
✓ 超出预期
4 分 - 良好
✓ 准确、完整、相关
✓ 格式正确、语气合适
✓ 符合预期
3 分 - 一般
✓ 基本准确、大部分完整
✓ 有轻微问题但不影响理解
✓ 勉强可用
2 分 - 较差
✗ 有明显错误或遗漏
✗ 格式不符或语气不当
✗ 需要修改才能使用
1 分 - 不可用
✗ 完全错误、无关或有害
✗ 无法使用
1.3 RAG 系统评估指标(RAGAS 框架)#
检索质量评估:
Context Precision(检索精准度)
= 相关文档数 / 检索文档总数
目标:> 0.8
Context Recall(检索召回率)
= 检索到的相关文档数 / 所有相关文档数
目标:> 0.7
生成质量评估:
Faithfulness(忠实度)
= 答案中基于上下文的陈述数 / 答案总陈述数
目标:> 0.8
评估方法:LLM 裁判检查答案是否基于检索内容
Answer Relevance(答案相关性)
= 答案与查询的语义相似度
目标:> 0.7
评估方法:嵌入向量余弦相似度
端到端评估:
Answer Semantic Similarity(语义相似度)
= 与参考答案的相似度
目标:> 0.75
评估方法:BERTScore 或嵌入向量相似度
第二部分:提示词评估与 A/B 测试#
2.1 提示词评估框架#
评估维度:
1. 准确性
- 输出是否准确
- 是否存在幻觉
- 是否遵循指令
2. 一致性
- 同样输入的输出是否一致
- 跨多次运行的稳定性
- 方差是否可控
3. 效率
- Token 使用量
- 响应延迟
- 成本
4. 鲁棒性
- 边界情况表现
- 对抗性输入表现
- 异常输入处理
2.2 A/B 测试设计#
实验流程:
第一步:定义假设
假设:新提示词能提高准确率 5%
第二步:选择指标
主指标:准确率
副指标:延迟、成本、用户满意度
第三步:确定样本量
基于:基线准确率、期望提升、统计功效
计算:使用功效分析工具
第四步:分流和运行
- 50% 用户使用旧提示词(对照组)
- 50% 用户使用新提示词(实验组)
- 运行 7-14 天
第五步:统计分析
- 计算两组的指标差异
- 进行 t 检验或卡方检验
- 检查 p 值 < 0.05
第六步:决策
- 如果显著,全量发布
- 如果不显著,回滚或继续优化
样本量计算:
n = 2 * (z_α/2 + z_β)² * p(1-p) / (p1 - p2)²
其中:
- z_α/2 = 1.96(95% 置信度)
- z_β = 0.84(80% 统计功效)
- p = 基线准确率
- p1 - p2 = 期望提升
例:基线 80%,期望提升 5%
n = 2 * (1.96 + 0.84)² * 0.8 * 0.2 / (0.05)²
≈ 1,537 样本
多臂老虎机算法(Thompson Sampling):
适用场景:
- 想快速找到最优提示词
- 不想浪费太多流量在差的版本上
原理:
- 动态调整流量分配
- 好的版本获得更多流量
- 坏的版本逐步被淘汰
优势:
- 比固定 50-50 分流更高效
- 减少实验期间的损失
2.3 提示词版本管理#
版本控制策略:
开发版(Dev)
- 频繁迭代
- 用于内部测试
- 可能不稳定
灰度版(Canary)
- 5-10% 用户
- 监控关键指标
- 发现问题快速回滚
生产版(Prod)
- 100% 用户
- 稳定可靠
- 定期评估
版本对比:
对比维度:
- 准确率对比
- 延迟对比
- 成本对比
- 用户反馈对比
对比方法:
- 在同一测试集上运行
- 使用相同的评估指标
- 记录详细的对比报告
第三部分:评估器的操作#
3.1 LLM-as-a-Judge 评估#
核心原理:
用高质量 LLM 作为评判者
↓
设计结构化评判提示词
↓
支持多维度打分
↓
定期与人工标注对齐
评判提示词设计:
[REDACTED]结构:
1. 角色定义
"你是一个专业的内容评估专家"
2. 评估维度
"请从以下维度评估:
- 准确性:是否符合事实
- 完整性:是否包含必要信息
- 相关性:是否回答了问题"
3. 评分标准
"5 分:完全符合所有标准
4 分:基本符合,有轻微不足
3 分:部分符合,有明显不足
2 分:大部分不符合
1 分:完全不符合"
4. 输出格式
"请以 JSON 格式输出:
{
'accuracy': 5,
'completeness': 4,
'relevance': 5,
'reasoning': '...'
}"
一致性验证:
步骤 1:用 LLM 评估 100 个样本
步骤 2:人工评估同样的 100 个样本
步骤 3:计算一致性指标
一致性指标:
- 完全一致率:> 80%
- 相差 1 分率:> 95%
- Cohen's Kappa:> 0.7
如果一致性不足:
- 优化评判提示词
- 调整评分标准
- 更换评判模型
避免常见偏差:
1. 位置偏见
问题:LLM 倾向于选择最后出现的选项
解决:随机打乱选项顺序
2. 长度偏见
问题:LLM 倾向于给长答案高分
解决:在提示词中明确说明长度不是评分标准
3. 自我偏见
问题:LLM 倾向于给自己生成的内容高分
解决:隐藏答案来源
4. 模型偏差
问题:不同模型的评分标准不一致
解决:定期与人工标注对齐
3.2 评估器的部署和监控#
评估流程自动化:
新版本发布
↓
自动触发评估任务
↓
在测试集上运行
↓
计算多维度指标
↓
与基线对比
↓
生成评估报告
↓
决策(发布/回滚/继续优化)
评估器性能监控:
监控指标:
- 评估延迟:应该 < 5 秒/样本
- 评估成本:应该 < 0.01 元/样本
- 评估一致性:应该 > 80%
- 评估覆盖率:应该 > 95%
告警规则:
- 延迟 > 10 秒 → 告警
- 成本 > 0.02 元 → 告警
- 一致性 < 70% → 告警
第四部分:人工标注和打标系统#
4.1 标注流程设计#
标注工作流:
第一步:准备标注数据
- 收集代表性样本
- 去重和清洗
- 随机打乱顺序
第二步:制定标注指南
- 明确标注任务
- 列举具体例子
- 说明边界情况
第三步:标注员培训
- 讲解标注指南
- 进行试标注
- 讨论分歧案例
第四步:正式标注
- 双标注(关键数据)
- 单标注(非关键数据)
- 定期审计
���五步:质量检查
- 计算标注一致性
- 识别问题标注员
- 反馈和改进
第六步:数据整理
- 合并标注结果
- 处理分歧
- 生成最终数据集
4.2 标注质量控制#
一致性指标:
Cohen's Kappa(双标注者)
κ = (P_o - P_e) / (1 - P_e)
其中:
- P_o = 观察到的一致率
- P_e = 期望的一致率
解释:
- κ > 0.8:很好
- 0.6 < κ ≤ 0.8:可以
- κ ≤ 0.6:需要改进
Fleiss' Kappa(多标注者)
用于 3 个或以上标注者的情况
Krippendorff's Alpha
更灵活,支持多种数据类型
标注员绩效评估:
指标 1:准确率
= 与最终标注一致的样本数 / 总样本数
目标:> 95%
指标 2:一致性
= 与其他标注员一致的样本数 / 总样本数
目标:> 90%
指标 3:效率
= 每小时标注样本数
目标:根据任务复杂度调整
指标 4:及时性
= 按时完成的任务数 / 总任务数
目标:100%
分歧解决机制:
当两个标注者意见不一致时:
方案 1:第三方仲裁
- 由经验丰富的标注员决定
- 适合关键数据
方案 2:讨论达成共识
- 标注员讨论分歧原因
- 更新标注指南
- 重新标注
方案 3:多数投票
- 3 个或以上标注者投票
- 适合众包场景
4.3 标注数据管理#
数据版本控制:
v1.0 - 初始版本
- 1000 个样本
- 双标注
- 一致性 85%
v1.1 - 改进版本
- 增加 500 个样本
- 优化标注指南
- 一致性 92%
v2.0 - 重大更新
- 新增标注维度
- 重新标注所有数据
- 一致性 95%
数据集分割:
训练集:60%
- 用于训练评估模型
- 用于提示词优化
验证集:20%
- 用于超参数调优
- 用于模型选择
测试集:20%
- 用于最终评估
- 不参与任何训练
第五部分:归因分析#
5.1 失败分类体系#
常见失败类型:
1. 检索失败(RAG 系统)
症状:检索不到相关文档
原因:
- 查询与文档不匹配
- 向量库质量差
- 检索参数不合适
解决:优化检索策略、更新向量库
2. 理解失败
症状:模型理解错了用户意图
原因:
- 提示词不清晰
- 用户表述模糊
- 上下文不足
解决:优化提示词、增加上下文
3. 生成失败
症状:模型生成了错误内容
原因:
- 幻觉
- 知识过时
- 模型能力不足
解决:更新知识库、���换模型
4. 格式失败
症状:输出格式不符合预期
原因:
- 提示词没有明确格式要求
- 模型没有遵循指令
解决:优化提示词、使用结构化输出
5. 超时失败
症状:请求超时
原因:
- 检索耗时过长
- 模型响应慢
- 网络问题
解决:优化流程、增加超时时间
6. 权限失败
症状:无权访问某些资源
原因:
- 用户权限不足
- 系统配置错误
解决:检查权限配置
5.2 归因分析流程#
数据驱动的归因:
第一步:收集失败案例
- 从生产环境收集
- 从用户反馈收集
- 从评估系统收集
第二步:分类失败
- 按失败类型分类
- 按严重程度分类
- 按影响用户数分类
第三步:根因分析
- 分析每个失败的根本原因
- 识别共同的根本原因
- 量化每个根本原因的影响
第四步:优先级排序
- 按影响范围排序
- 按修复难度排序
- 按投入产出比排序
第五步:制定改进方案
- 针对每个根本原因
- 设计改进方案
- 评估改进效果
第六步:跟踪改进
- 监控改进后的指标
- 验证改进是否有效
- 持续优化
失败分析模板:
失败 ID:FAIL-2024-001
失败类型:检索失败
严重程度:高
影响用户数:150
症状:
用户查询"商品价格",系统返回无关结果
根本原因分析:
1. 查询理解:正确理解为"商品价格查询"
2. 检索:检索到的文档与查询不匹配
3. 排序:相关文档排名靠后
主要根本原因:
向量库中缺少商品价格相关的文档
改进方案:
1. 补充商品价格文档
2. 优化向量化方法
3. 调整检索参数
预期效果:
- 准确率从 60% 提升到 85%
- 影响用户数减少 80%
实施时间:3 天
5.3 持续改进循环#
周期性评估和改进:
周报(每周)
- 关键指标汇总
- 新增失败案例分析
- 改进方案进展
月报(每月)
- 指标趋势分析
- 失败类型分布
- 改进效果评估
- 下月优化方向
季报(每季度)
- 整体系统评估
- 架构优化建议
- 资源投入规划
第六部分:Langfuse 集成实战#
6.1 评估流程集成#
Langfuse 中的评估工作流:
第一步:记录 Trace
- 每个请求自动记录完整链路
- 包括输入、输出、中间步骤
第二步:添加评分
- 在 UI 中手动打分
- 或通过 API 自动打分
- 支持多维度评分
第三��:LLM 裁判评估
- 定义评判提示词
- 自动运行评估
- 记录评估结果
第四步:人工标注
- 在 Annotation Queue 中标注
- 支持多标注者
- 自动计算一致性
第五步:数据集管理
- 创建测试数据集
- 版本控制
- 基准对比
第六步:分析和优化
- 查看评估报告
- 对比不同版本
- 识别改进方向
6.2 关键指标监控#
在 Langfuse Dashboard 中设置:
准确率趋势
- 每天的准确率
- 周均值、月均值
- 与基线对比
成本监控
- 每天的 Token 成本
- 按模型分类
- 成本趋势
延迟分布
- P50、P95、P99 延迟
- 按节点分类
- 瓶颈识别
错误率
- 每天的错误数
- 错误类型分布
- 错误趋势
6.3 提示词版本管理#
在 Langfuse 中管理提示词版本:
创建提示词
- 定义提示词模板
- 添加变量占位符
- 设置默认值
版本控制
- 每次修改自动创建新版本
- 记录修改历史
- 支持版本对比
发布管理
- 开发版:频繁迭代
- 灰度版:小流量测试
- 生产版:全量发布
性能对比
- 对比不同版本的指标
- 识别最优版本
- 自动推荐
第七部分:最佳实践总结#
7.1 评估体系建设路线图#
第一阶段(第 1-2 周):基础建设
- 定义评估指标体系
- 建立基础的人工标注流程
- 集成 Langfuse 记录 Trace
第二阶段(第 3-4 周):自动化评估
- 实现 LLM-as-a-Judge 评估
- 建立自动化评估流程
- 验证评估一致性
第三阶段(第 5-6 周):A/B 测试框架
- 设计 A/B 测试流程
- 实现流量分流
- 进行首次 A/B 测试
第四阶段(第 7-8 周):持续改进
- 建立周期性评估
- 实现归因分析
- 形成改进闭环
7.2 常见陷阱#
陷阱 1:评估指标过多 ❌ 定义 20+ 个评估指标 ✅ 精选 5-8 个核心指标,定期审视
陷阱 2:忽视评估一致性 ❌ 直接使用 LLM 评估,不验证一致性 ✅ 定期与人工标注对齐,确保一致性 > 80%
陷阱 3:样本量不足 ❌ 用 10 个样本做 A/B 测试 ✅ 根据功效分析计算所需样本量
陷阱 4:评估数据污染 ❌ 用训练数据做评估 ✅ 严格分离训练集、验证集、测试集
陷阱 5:忽视成本 ❌ 每个请求都进行完整评估 ✅ 采样评估,定期全量评估
7.3 关键成功因素#
1. 清晰的指标定义
- 每个指标都有明确的计算方法
- 每个指标都有明确的目标值
- 定期审视和调整
2. 高质量的标注数据
- 代表性的样本
- 一致的标注标准
- 定期质量检查
3. 自动化的评估流程
- 减少人工干预
- 提高评估效率
- 便于持续监控
4. 完整的可观测性
- 记录每个请求的完整链路
- 支持快速问题定位
- 便于根因分析
5. 持续的改进循环
- 定期评估和分析
- 快速迭代和优化
- 跟踪改进效果
总结#
一个完整的 LLM 应用评估体系包括:
- 多维度指标体系 - 准确性、相关性、完整性等
- 提示词评估和 A/B 测试 - 科学的优化方法
- 自动化评估器 - LLM-as-a-Judge 和自动化流程
- 人工标注系统 - 高质量的标注数据和质量控制
- 归因分析 - 理解失败原因,持续改进
- Langfuse 集成 - 完整的可观测性和管理平台
通过这个体系,你可以从"能用"进阶到"好用",最终实现"卓越"。
评论
还没有评论,来发第一个吧