12 篇
2 个三级分类
信息追踪、阅读输入与阶段性观察记录。
专题分组
这是一篇记录将 Tello 美国实体手机号转入 Google Voice 的操作笔记,重点在于从 Tello 后台发起 port out,并在 Google Voice 的号码转入页面完成接收。作者先说明了一个容易卡住的前提:Tello 账户地址曾因避税设置为香港,实际尝试时无法顺利转入 Google Voice,后来在 Tello 对美国境外地址收税的限制下,改选美国低税区 Las Vegas 地址后继续操作。流程核心是在 Tello 后台选择 Google Voice port out,系统会提供两个用于转出的码,其中账号信息和验证码会在 Google Voice 侧填写。随后进入 Google Voice porting 页面,按要求支付 20 美元,等待约两天即可完成转入。笔记还提示这种操作可能带来两个 Google Voice 号码的结果,但成功条件依赖地址区域、税费规则和 Google Voice 转入校验。适合已有 Tello 实体号、希望保留号码并迁移到 Google Voice 的用户,用作核对关键入口、费用和地址限制的简要参考。
![[转] codex 使用配置](https://cdn.jacin.me/public/2026/04/9d9b951bc56b0eb891c9df0713b986ee-1775662342063.png) AI见闻
AI见闻这是一份围绕 Codex 本地使用治理的配置摘录,先交代 `~/.codex` 目录中 `config.toml`、`auth.json`、`instructions.md`、`version.json`、`token` 等文件的职责,再指出 Codex 主配置采用 TOML 格式,位置在 `~/.codex/config.toml`。重点内容是一份全局 `AGENTS.md` 示例,它被类比为 Claude Code 的 `CLAUDE.md`,用于在 `~/.codex` 范围内约束 Codex 的默认行为,并允许子目录同名文件覆盖。示例提示词强调用户显式命令、子目录指南、根目录指南和其他约定之间的优先级,同时要求在冲突、工具降级、外部检索、文件变更和交付环节保留可审计说明。正文还列出本地检索、`apply_patch`、安全 shell、Sequential Thinking、Context7、Fetch、Playwright 等工具的使用顺序与降级条件,并把 Research、Plan、Implement、Verify、Deliver 固化为标准工作流。其价值不在于讲解 Codex 功能细节,而是提供一套偏工程治理的全局提示词框架,帮助开发者统一安全边界、证据来源、质量门槛、交付说明和风险留痕。需要注意的是,文中部分路径、工具清单和质量指标具有强烈个人环境特征,适合参考结构与约束思路,实际落地时应按自己的 Codex 配置、可用 MCP 工具和项目流程裁剪。
 即时热点记录
即时热点记录这篇笔记记录了一次 Claude 账号从 Apple ID 隐藏邮箱登录方式迁移到自建邮箱账号的操作过程,背景是原先使用 Apple ID 加 giffgaff 接码注册后,每次确认登录邮箱都要回查隐藏邮箱信息,使用体验不够方便。正文给出的注册路径是使用 5sim 接码平台,进入 5sim 后选择法国地区和 Virtual51 运营商,用于完成新账号所需的手机验证。迁移部分重点不是简单重新注册,而是先在旧 Claude 账号中导出历史记录,保留 conversations.json 这类包含对话内容、时间和模型信息的导出文件。随后作者提供了一段用于“记忆提取后转移”的提示词,要求 Claude 完整分析导出的 conversations.json,从历史对话中提取身份背景、回复风格、常用规则、长期项目、决策习惯和特殊要求等核心记忆,并整理为可导入 Memory 的 Markdown 文本。提示词还限制了输出结构、第二人称写法、字符上限和额外概览信息,方便在新账号中重建长期上下文。适合需要更换 Claude 登录方式、迁移旧账号对话记忆,或想把历史聊天记录整理成可复用个人偏好配置的用户参考,但接码平台、地区和运营商选择属于当时实践记录,实际可用性仍需按注册时环境确认。
 AI见闻
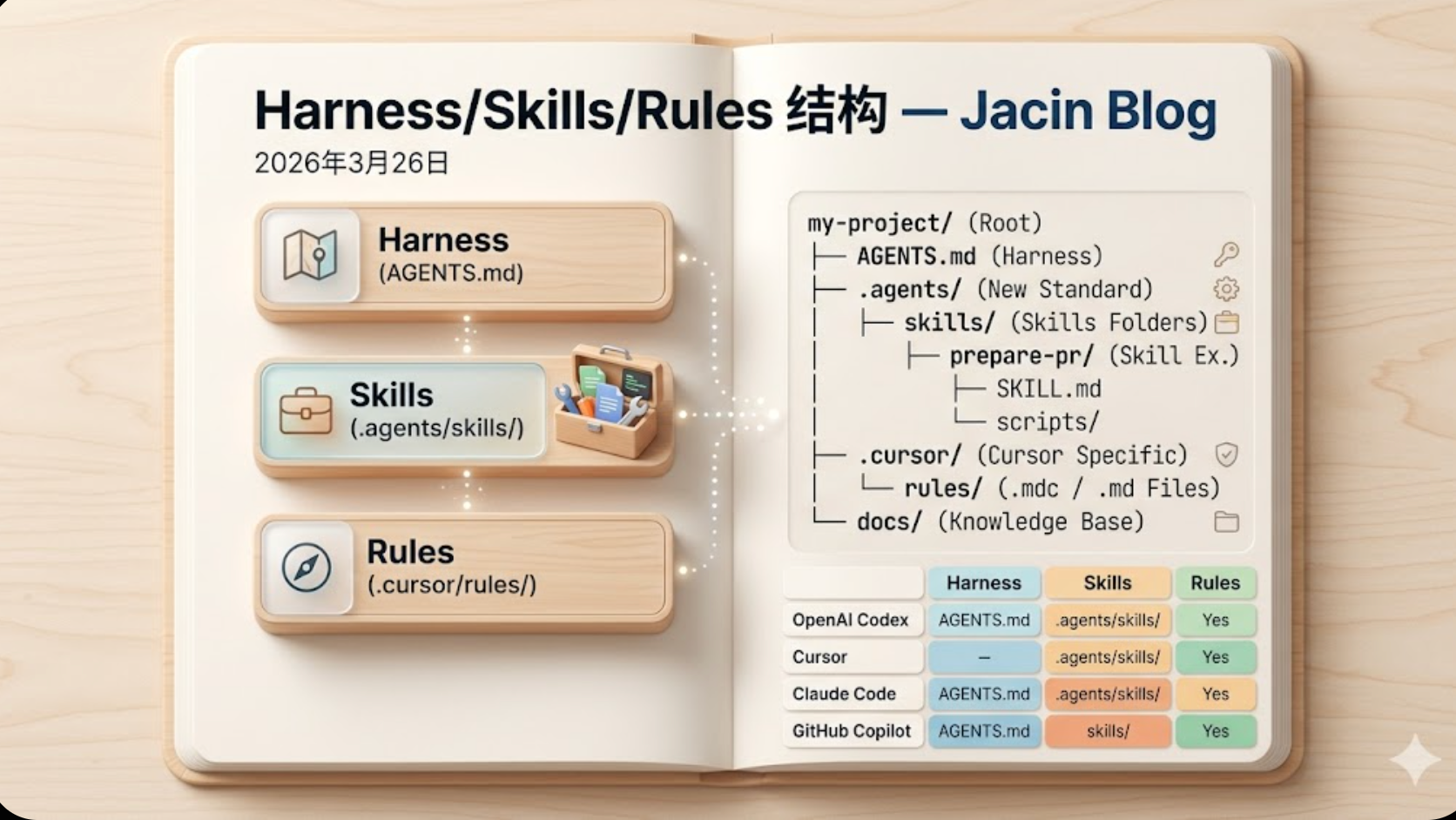
AI见闻这篇笔记聚焦 2026 年 Agent 项目中 Harness、Skills 与 Rules 的目录组织方式,给出一套兼顾 Codex、Cursor、Claude Code 与 GitHub Copilot 的项目结构参考。核心建议是把 AGENTS.md 放在项目根目录,作为 Agent 的规则、约束与项目概览入口,并允许在子模块中继续放置子 AGENTS.md 形成层级继承。Skills 推荐集中放在跨工具通用的 .agents/skills/ 下,每个 Skill 必须是独立文件夹,至少包含带 YAML 前言的 SKILL.md,也可以附带 scripts、references、assets 等资源。Rules 则主要是 Cursor 的专属机制,放在 .cursor/rules/ 中,以 .mdc 或 .md 文件形式存在,并支持 glob 路径匹配、智能匹配和手动触发。文中还区分了不同工具的惯例:Codex 更依赖 AGENTS.md 与 docs/ 知识库,Cursor 可并存 .agents/skills 与 .cursor/skills,Claude Code 可使用 CLAUDE.md 或 .claude/skills,Copilot 则偏轻量并使用 .github/skills。适合正在整理多 Agent 工具链配置、希望减少目录分裂和规则重复的开发者,用来快速判断哪些文件应作为跨工具标准,哪些只应保留在工具专属目录中。
Antigravity 虽然是 VS Code fork,但默认接入的是 Open VSX 而不是 Microsoft 官方 VS Code Marketplace,因此可搜索到的扩展数量更少,部分主题、语言支持和 AI 类插件可能缺失。文章把这个问题放在 Antigravity 作为第三方 fork 的授权背景下解释:官方 Marketplace 并非默认可用,而 Antigravity 又更侧重 agentic AI 任务,插件生态和兼容性仍不如 Cursor 这类已获得完整 marketplace 授权并做过优化的产品。解决路径是进入 Antigravity 设置中的 Editor 配置,把 Marketplace Item URL 改为 https://marketplace.visualstudio.com/items,并把 Marketplace Gallery URL 改为 https://marketplace.visualstudio.com/_apis/public/gallery,重启后即可在扩展面板搜索更多 VS Code 插件。文章也提醒,即便切换源后能安装更多扩展,仍可能遇到扩展面板卡顿、安装失败或激活异常等兼容性问题,因为 Antigravity 的 UI 和 agent 能力经过定制,插件支持还处在不成熟阶段。对于少数无法直接搜索或属于 Cursor 独占的扩展,可通过下载 .vsix 文件,再在扩展面板的 Install from VSIX 中手动安装。整体适合正在把 Antigravity 当作 VS Code/Cursor 替代品使用、但发现插件缺失或扩展搜索结果不足的开发者,用来快速判断问题原因、调整插件源并了解后续兼容风险。
 AI见闻
AI见闻这是一则关于在 Chrome 中手动启用 Gemini/Glic 相关实验功能的简短配置记录,适用于想提前查看浏览器 AI 助手入口或界面变化的用户。操作路径是新建标签页后在地址栏输入 chrome://flags,进入实验功能页面,再分别开启 Tabstrip Combo Button、Glic、Glic Z Order Changes 和 Glic actor 等选项。正文说明这些开关主要与 Chrome 推出的 AI 助手 Glic 以及界面布局优化有关,开启后通常不会对日常浏览造成明显影响。完成修改后,Chrome 会在右下角显示重启按钮,需要重启浏览器后配置才会真正生效。文章的价值在于把需要开启的 flags 名称和生效步骤集中列出,减少用户在实验选项中逐项查找和判断的成本。需要注意的是,flags 属于浏览器实验功能,具体入口、命名和可用性可能随 Chrome 版本变化,因此更适合作为临时尝鲜或功能验证参考,而不是稳定功能配置指南。
这段笔记围绕二语习得中的母语干扰展开,把学习者在理解英语时依赖中文中介的现象,放到语言学中 L1 interference 的框架下说明。内容先以一段较正式的英文自我介绍和助人定位开场,随后转入学习者对自身困境的反思:即便具备一定英语输入能力,理解过程仍可能先经过中文转换,而不是直接抵达意义。文章给出的核心判断是,这种状态并非个体异常,而是二语习得中常见且典型的阶段,关键不在于否定母语作用,而在于逐步减少对它的依赖。其解决思路强调 deliberate, sustained practice,也就是持续、有意识的练习,通过反复接触和使用英语来强化“英语形式—意义”之间的直接神经通路。文中用肌肉记忆作类比,说明直觉化理解并不是一次顿悟,而是由重复训练积累出来的加工能力。适合正在从翻译式理解转向英语直接思维的学习者阅读,可帮助他们重新定位卡顿、翻译依赖和理解迟滞等问题,并把焦点放在长期训练路径上。
ENGLISH-study 类别可定位为英语学习相关内容的集中归档入口,用于收纳围绕词汇、语法、阅读、听力、写作、口语练习以及学习方法整理的笔记与资料。它的价值在于把语言学习过程中的零散记录按主题沉淀下来,方便读者快速判断某篇内容是偏知识讲解、练习记录、资源整理还是学习策略。与偏技术、工具或日常随笔类内容相比,该分类应突出英语能力提升这一主线,避免把无明确英语学习目标的泛泛摘录混入其中。后续使用时可进一步明确收录边界,例如是否包含考试备考、英文资料精读、AI 辅助学英语等子话题,以及是否需要按学习阶段或技能方向拆分子类。对于正在整理个人英语学习体系、查找学习材料或复盘训练方法的读者,这一类别能提供更清晰的入口和持续积累的知识结构。
“个人随机 NOTE”适合承载作者在日常学习、使用工具、阅读资料或处理事务时形成的零散记录,重点不在系统教程或完整方案,而在保留当时的想法、片段线索和临时判断。它与专题类技术文章的区别在于结构更轻、主题更开放,内容可以是短观察、待验证的问题、经验备忘、资料索引或阶段性想法,不要求形成完整论证。这个类别的价值在于为那些暂时无法归入明确技术栈、项目复盘或知识专题的内容提供稳定入口,避免有记录价值的信息被迫拆散或遗失。使用时应尽量保持可读性,说明记录背景、触发原因和可能用途,避免只留下无法复用的碎片。若某篇 NOTE 后续扩展为完整教程、排查报告或专题文章,应迁移到更准确的类别中;若长期内容高度集中,也可以再拆分为独立主题。该类别更适合关注作者个人知识流、临时经验和思考轨迹的读者。
这份笔记围绕 2026 年 2 月海外四大前沿模型 API 的调用成本展开,把 xAI Grok、OpenAI GPT、Google Gemini 与 Anthropic Claude 的代表型号放在同一张表中比较,核心维度包括每百万 tokens 输入价、输出价、上下文窗口和产品定位。表中最突出的结论是 Grok-4.1-fast 与 Grok-4-fast 系列以 $0.20 输入、$0.50 输出和 2M 上下文形成明显低价区间,适合高调用量、批量处理和工具调用场景,而旧版 Grok-4-0709 价格显著更高且上下文仅 256K。OpenAI 侧呈现分层策略:GPT-5.2 标准旗舰偏向编码和代理任务,支持缓存输入低价;GPT-5.2 pro 面向精密任务但成本极高;GPT-5 mini 则承担轻量快速版本的角色。Gemini 3 Pro 采用随长 prompt 变化的阶梯价格,输入约 $2.00-$4.00、输出约 $12.00-$18.00,并以 1M-2M 上下文和多模态能力作为主要卖点。Claude 4 / 3.5 Sonnet 级模型价格处在较高区间,强调高智能、安全、缓存与工具能力,同时保留 Haiku 等更廉价变体。它适合需要快速判断模型选型成本的 AI 应用开发者、后端工程师和产品负责人,用来在预算、上下文长度、智能水平与多模态或安全需求之间做初步取舍。