 AI 大模型开发
AI 大模型开发25 分钟
Codex 现在该怎么用:从“让 AI 写代码”到“搭一个可验证的开发工作流”
随着 Codex 从“会写代码的聊天框”演变为可管理的开发代理,高效用法的核心已转向构建“看得见、说得清、验得过、沉淀得下”的四步工作流:先通过 Appshots、浏览器标注或 Computer Use 让 Codex 看见现场上下文,再以包含目标、边界和验收标准的任务契约替代模糊提示,然后强制要求测试、lint、typecheck 和 diff 作为交付证据,最后将反复使用的规则和流程沉淀为 AGENTS.md、config.toml 或 Skill。文章详细区分了 Plan mode、Goal mode 的适用场景,给出了普通任务、前端调整、长任务 `/goal` 三套可直接复用的提示词模板,并强调团队不应只看代码行数,而应关注重复排查流程的减少和规则的可复用性。对于已熟悉 Codex 但期望突破玩具感、进入生产环境的后端、前端或全栈开发者,本文提供了从单次对话框到可控协作工作流的完整升级路径。
记忆拼接
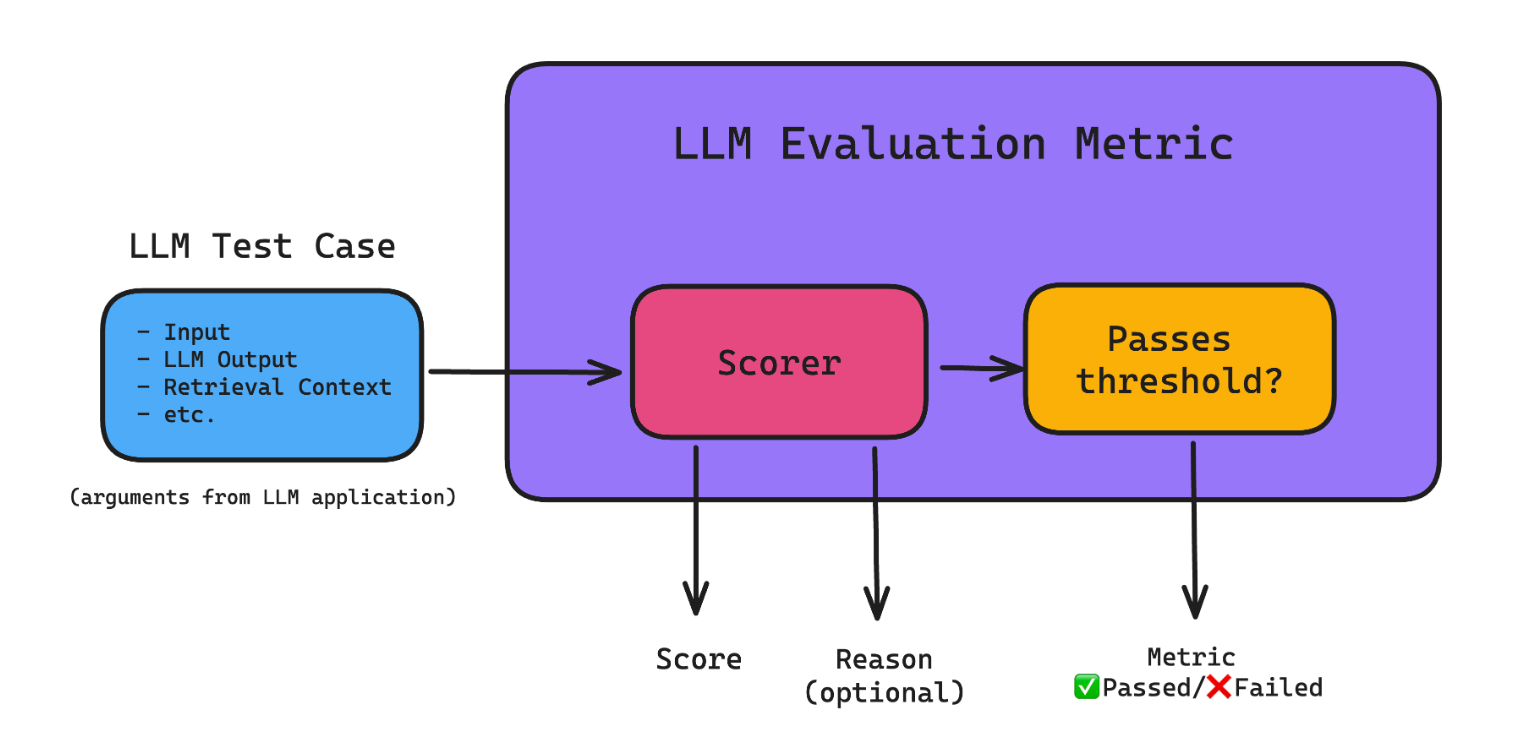
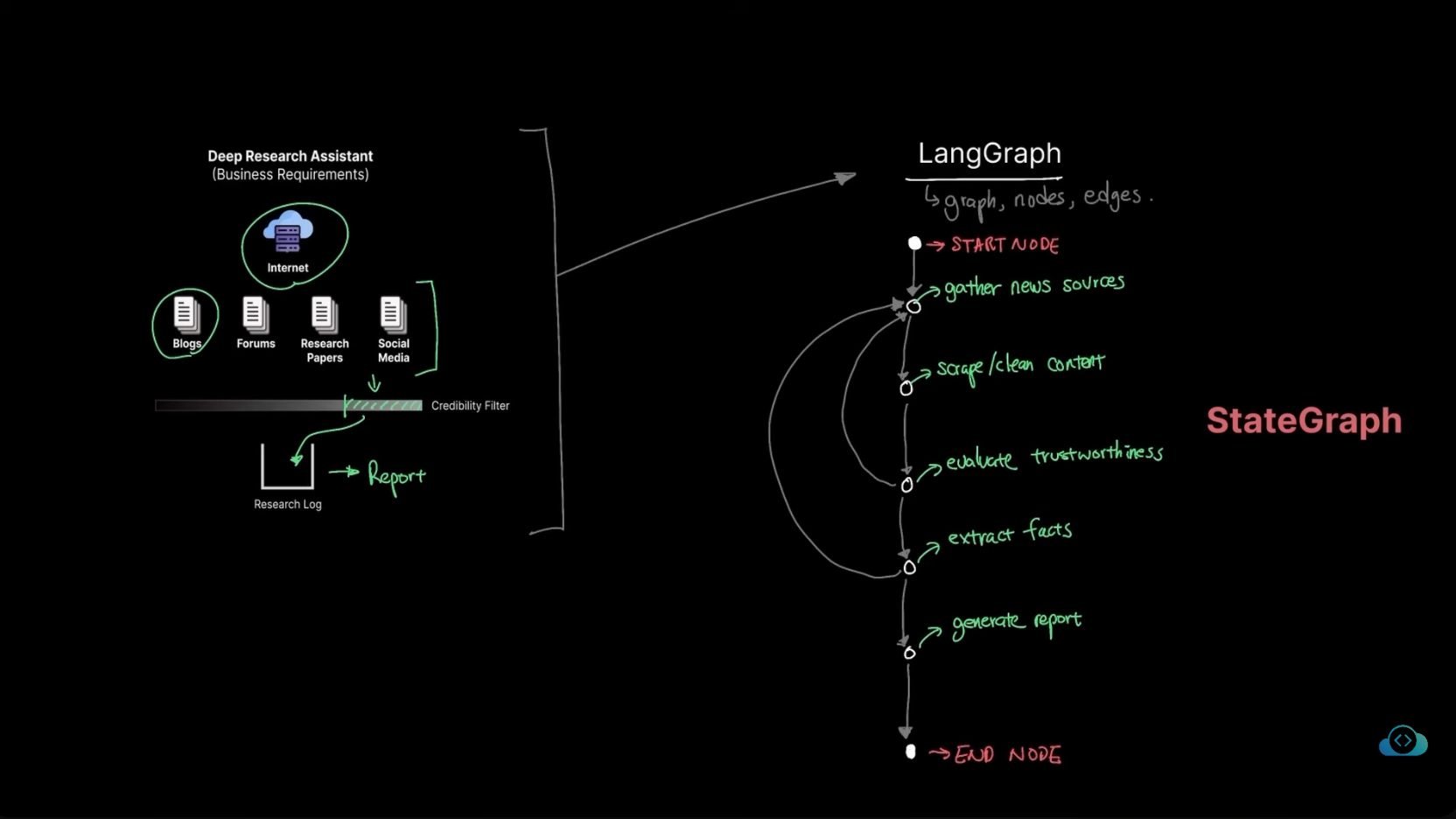


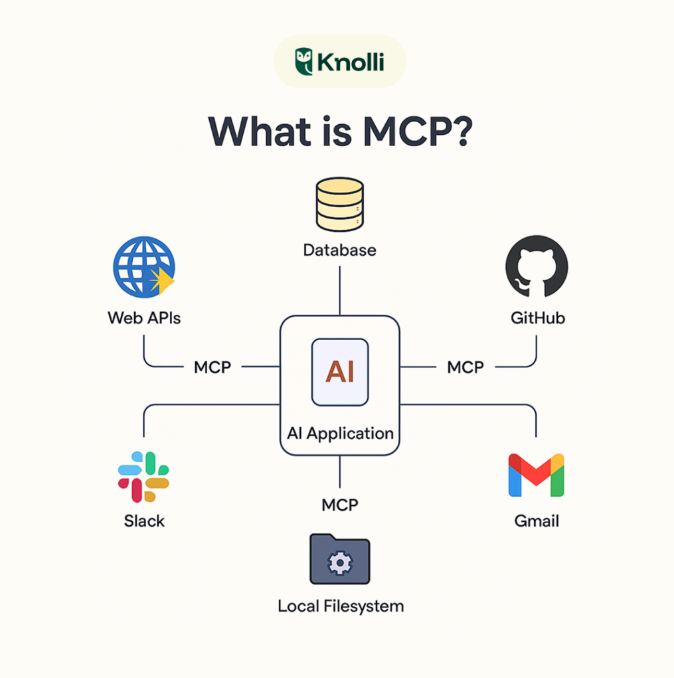

![[转]LangGraph完整指南](https://cdn.jacin.me/public/2026/04/b6f169b921a903d921d20e584751d438-1775490302585.png)