下级分类
AI 大模型开发26 篇
模型应用、提示工程与 AI 开发实践。
专题分组
 AI 大模型开发
AI 大模型开发随着 Codex 从“会写代码的聊天框”演变为可管理的开发代理,高效用法的核心已转向构建“看得见、说得清、验得过、沉淀得下”的四步工作流:先通过 Appshots、浏览器标注或 Computer Use 让 Codex 看见现场上下文,再以包含目标、边界和验收标准的任务契约替代模糊提示,然后强制要求测试、lint、typecheck 和 diff 作为交付证据,最后将反复使用的规则和流程沉淀为 AGENTS.md、config.toml 或 Skill。文章详细区分了 Plan mode、Goal mode 的适用场景,给出了普通任务、前端调整、长任务 `/goal` 三套可直接复用的提示词模板,并强调团队不应只看代码行数,而应关注重复排查流程的减少和规则的可复用性。对于已熟悉 Codex 但期望突破玩具感、进入生产环境的后端、前端或全栈开发者,本文提供了从单次对话框到可控协作工作流的完整升级路径。
 AI 大模型开发
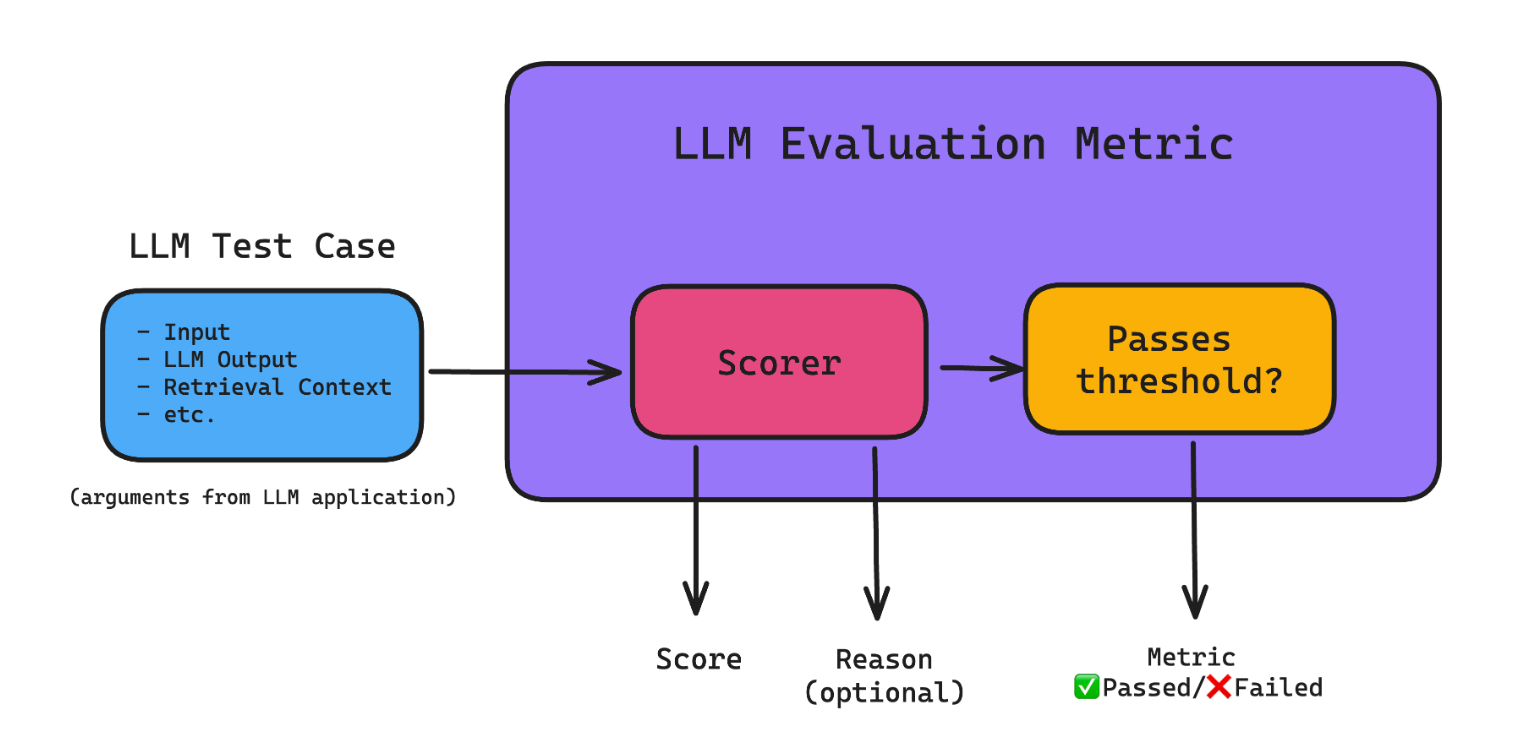
AI 大模型开发这是一份面向 LLM 应用质量工程的评估体系笔记,核心关注如何把模型输出从上线后的偶发检查,转为可监控、可比较、可归因的持续改进闭环。正文先建立多维指标框架,将准确性、相关性、完整性、格式合规和语气适配按权重拆分,并补充 RAGAS 中 Context Precision、Context Recall、Faithfulness、Answer Relevance 等检索与生成指标的目标值和评估方法。随后围绕提示词优化给出 A/B 测试流程、样本量计算思路、多臂老虎机分流策略,以及 Dev、Canary、Prod 的版本管理方式。评估器部分重点说明 LLM-as-a-Judge 的结构化提示词、与人工标注的一致性校验、常见偏差规避,以及评估延迟、成本、覆盖率等运行监控。文章还覆盖人工标注工作流、Kappa 等一致性指标、分歧处理、数据集版本与训练/验证/测试集划分,并用失败分类和归因模板连接到后续优化。最后以 Langfuse 为例串起 Trace 记录、评分、Annotation Queue、数据集管理、Dashboard 监控和提示词版本对比,适合正在搭建 RAG、智能客服或其他生产级 LLM 应用评估闭环的开发与平台团队参考。
 AI 大模型开发
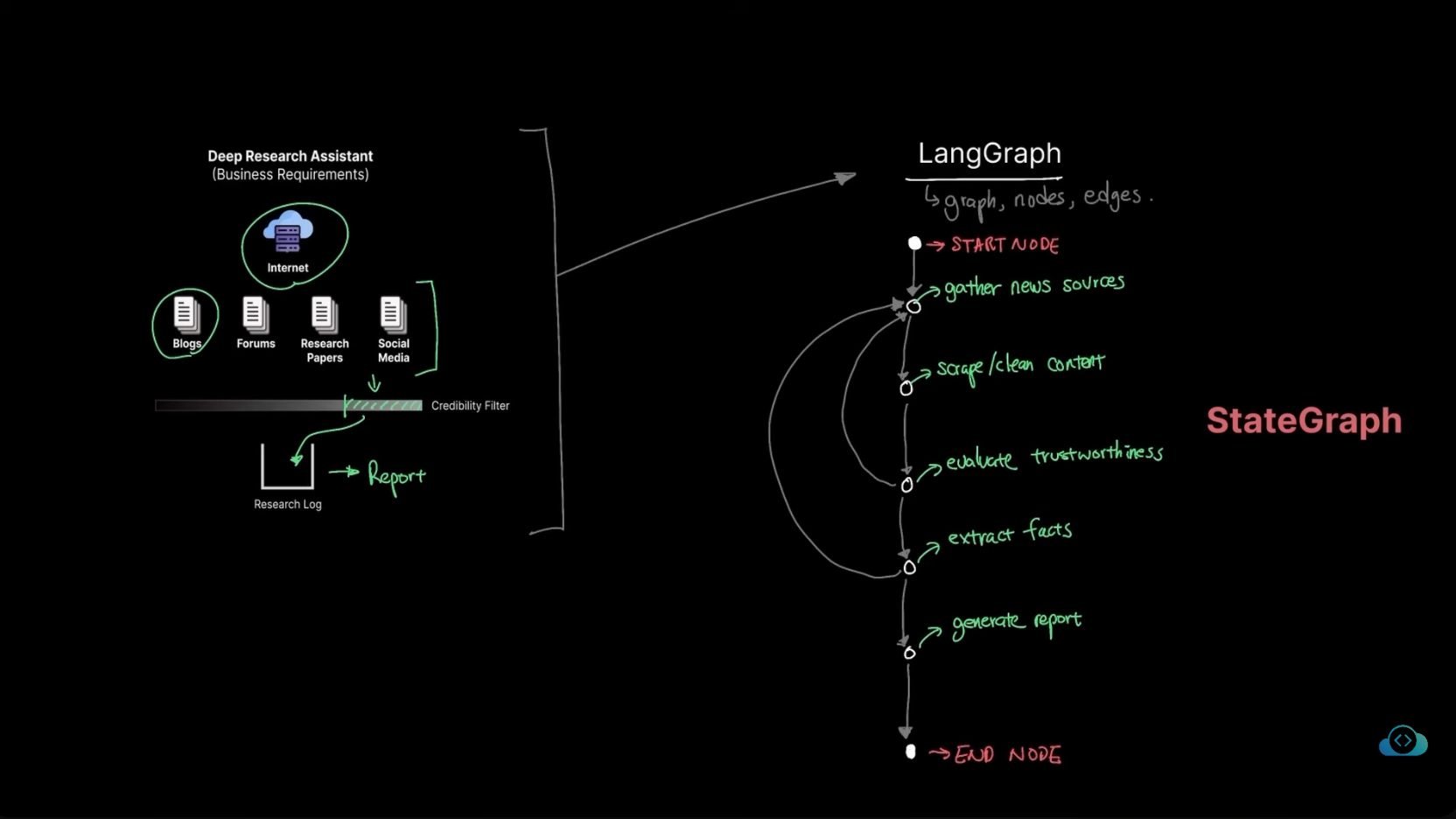
AI 大模型开发这是一份面向复杂 AI Agent 设计与面试准备的 LangGraph 导读,核心对象是其状态驱动的有向图工作流模型,以及它相对 LangChain 线性 Chain 在动态分支、并行执行和显式状态管理上的差异。内容围绕 State、Reducer、Node、Edge、Conditional Edge 等关键概念展开,说明 State 如何承担节点通信和多会话隔离,Reducer 如何处理并发写入时的消息追加、列表合并或覆盖策略。文章还梳理了条件路由、thread_id 与 Checkpointer、Fan-out/Fan-in、Early Exit、Fallback 等常见设计模式,用客服 Agent 场景串联商品查询、订单查询、投诉处理、多用户并发和 SLA 保证的系统设计思路。可靠性部分强调 Node 应保持单一职责、幂等、异步优先并具备错误处理,路由函数也应只依赖 State,避免随机数、时间或全局变量造成重试和回放不一致。可观测性则以 Langfuse 为例,覆盖 Trace、Token 成本、延迟、提示词版本和 A/B 测试等运维视角。适合正在从简单 LLM 调用转向可生产化 Agent 编排的后端开发、AI 应用开发者和准备相关系统设计面试的读者。
 AI 大模型开发
AI 大模型开发Agent Harness 被界定为大模型之外的运行时系统,用来把原本不可控的 LLM 能力纳入可编排、可审计、可上线的 Agent 工程框架中。文章围绕 Agent = Model + Harness 的基本公式,拆解接入、编排、工具、记忆、安全防护、观测评测六层架构,说明长时多轮任务需要稳定的会话容器、受控的 TAO/ReAct 循环、最大迭代次数、错误处理和 fallback,而不是让模型无限自由发挥。工具层强调注册、schema、权限、超时、重试和熔断,建议从 3 到 5 个核心工具起步,避免工具膨胀造成模型选择混乱。记忆层区分短期状态与长期事实,重点不在“存得多”,而在上下文预算、滚动摘要、按需召回和防止记忆污染当前任务。安全部分覆盖 prompt injection、敏感工具拦截、高风险操作确认、沙盒、审计日志,并补充 Skills 执行中的提示词约束、命令白名单、隔离和结果过滤。文章还把 Harness 与 Skills、MCP 的关系放在同一框架下理解:Skills 偏本地工作流,MCP 偏远程能力接入,Harness 负责整体编排;其中 Hermes Agents 部分明确属于基于趋势的推测。适合正在把 Agent 从 Demo 推向企业级应用的 AI 应用开发者、后端工程师和平台工程团队,用来建立可靠性、安全性和可观测性的工程检查清单。
 AI 大模型开发
AI 大模型开发这篇笔记聚焦 Skills 挂载到 Shell 环境后的执行安全,核心判断是不能只依赖模型自觉遵守规则,而要由后端对命令生成、执行环境和输出结果形成闭环控制。内容按四层防护展开:先在 SKILL.md 中声明允许读取、创建或修改的范围,并明确禁止删除系统文件、访问敏感目录、执行网络命令等高风险行为;随后通过命令白名单和正则黑名单,在执行前拦截 rm -rf、sudo、chmod 777、写入 /etc 等危险模式。执行阶段建议放入 Docker 沙盒,限制镜像、内存、CPU、超时时间,关闭网络,并将 /data 以只读方式挂载,降低命令越权和资源滥用的影响面。最后一层是结果过滤与审计,记录执行命令和输出长度,同时对 password、token、api_key 等敏感字段脱敏,并截断过长输出,避免把风险从执行环节转移到返回内容。它适合正在把 AI Skills、Agent 工具调用或自动化脚本接入后端的开发者,用来建立一套可落地的最小安全框架。需要注意的是,提示词约束只是第一道软边界,真正的安全性来自白名单校验、隔离运行和输出治理的组合,而不是让模型“更聪明”。
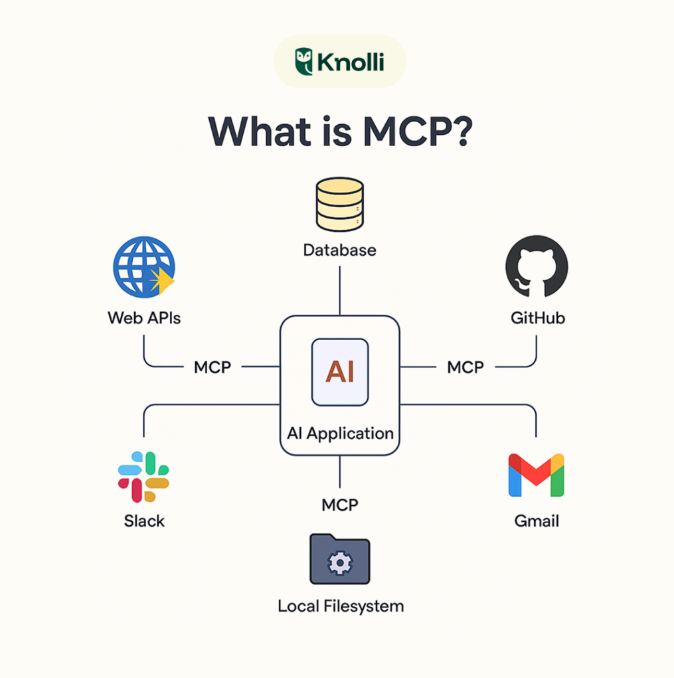 AI 大模型开发
AI 大模型开发这是一篇面向 AI 应用开发者的 MCP 开发入门与实践笔记,围绕 Model Context Protocol 如何把 Claude、IDE、ChatGPT 等 AI 客户端与外部系统标准化连接起来展开。内容先说明 MCP 的分层架构:Host、Client、JSON-RPC 2.0 协议、STDIO 或 HTTP 传输以及 Server 侧能力提供,并将 Tool、Skill、MCP 放在执行方式和适用场景上对比,帮助读者判断何时需要协议化接入而不是单个工具或本地技能。实践部分给出 Python 环境准备、uv 依赖安装、FastMCP 服务器开发示例,包括天气查询、SQLite 数据库查询,以及 STDIO 模式下日志必须写入 stderr、避免破坏 JSON-RPC 消息的注意事项。客户端部分展示了通过 ClientSession、stdio_client 连接服务器、列出工具、结合 Anthropic API 处理 tool_use 循环并回传工具结果的完整流程,同时补充 OpenAI Responses API 中以 mcp 工具类型接入远程服务器、使用 allowed_tools 控制暴露范围的写法。后续章节梳理 Tools、Resources、Prompts 三类核心能力、工具列表变化通知机制,以及开发工具、数据分析、业务自动化和旅行规划等应用场景,适合想从概念、协议结构到最小可运行代码建立 MCP 开发框架的读者。
 AI 大模型开发
AI 大模型开发这篇指南把 AI Skills 定位为挂载在执行环境上的任务知识包,而不是单纯的 shell 工具,核心由 SKILL.md、执行步骤、策略约束和可选辅助脚本组成。正文先区分 Tool、Skill 与 MCP:Tool 是具体能力,Skill 是能力的使用手册和执行 SOP,MCP 则负责把模型连接到外部工具和数据源。文章给出官方目录结构、SKILL.md frontmatter 中 name 与 description 的必需字段,并用 CSV 汇总报告示例展示如何声明触发条件、编排执行步骤和返回结果。随后扩展到 OpenAI Responses API 的多 Skills 配置、Claude Code 中通过 slash commands 暴露预置或自定义 Skills,以及代码格式化 Skill 的目录创建、说明文件和 Python 辅助脚本实现。实践部分强调单一职责、清晰命名、准确 description、脚本可复用,并列出数据处理、文档生成、测试辅助、代码质量检查等模板方向。文章也覆盖常见排查与优化:未触发通常来自描述不清,执行失败可能是依赖缺失,性能问题可通过缓存、异步、增量处理和资源限制缓解,适合正在设计可复用 AI 任务能力包的开发者和 AI 工程实践者。
![[转]LangGraph完整指南](https://cdn.jacin.me/public/2026/04/b6f169b921a903d921d20e584751d438-1775490302585.png) AI 大模型开发
AI 大模型开发这是一篇围绕 LangGraph 的转载型技术导读,聚焦它如何在 LangChain 生态中承担复杂 Agent 工作流编排角色:LangChain 更像模型、提示词和工具等“零件库”,LangGraph 则通过图结构把这些组件组织成可循环、可分支、可维护的执行流程。正文以图、节点、边、状态四个核心概念展开,说明状态用于在节点间保存对话历史、中间结果和决策记录,节点负责单一计算职责,普通边与条件边决定流程流转,而 StateGraph 则用于定义、连接、编译并运行完整工作流。示例部分给出基于 TypedDict、ChatOpenAI、StateGraph、入口节点和 END 的最小代码骨架,帮助读者理解从状态定义到图编译、调用执行的基本路径。文章还归纳了链式、路由、循环和协作四类常见工作流,分别对应顺序任务、动态分流、迭代优化和多 Agent 分工协作等场景。进阶部分进一步覆盖 checkpointer 持久化、检查点回溯与 Time Travel、人机协作中断恢复、多 Agent 通信协调,以及 stream/astream 支持的流式输出。适合已了解 LangChain 基础、希望把 LLM 调用升级为可控 Agent 系统的 AI 应用开发者,用来建立 LangGraph 的概念框架和工程切入点。
这篇笔记聚焦 LangChain embeddings 的本地文件缓存处理,核心场景是避免重复调用 embedding 模型,同时保证缓存命中结果不会因模型差异而混用。正文用 `LocalFileStore("./.cache/embeddings/", update_atime=True)` 和 `CacheBackedEmbeddings.from_bytes_store(...)` 展示了基本写法,并强调同一段文本在不同模型下会得到不同向量,因此缓存 key 需要通过 `namespace=openai_embeddings.model` 区分模型命名空间,避免串缓存。`LocalFileStore` 在读取缓存文件时可以主动刷新 atime,也就是最后访问时间,用来弥补某些文件系统默认不可靠更新 atime 或更新策略较弱的问题。缓存代理的工作流程是先由输入文本生成 key,再查本地 store,命中则直接返回 embedding,未命中才调用 `openai_embeddings` 并把结果写回缓存。文章还解释了 mtime、ctime、atime 的区别,并围绕 atime 引出缓存淘汰策略:LRU 会优先删除很久没访问的项目,适合 embedding 缓存、页面缓存、Redis 热数据和数据库 buffer pool 等大多数热点访问场景;MRU 则优先删除刚访问过的项目,更适合顺序扫描大文件、批处理或一次性遍历数据集这类短期不会回头访问的场景。读者可以据此理解 LangChain 缓存 embedding 的关键配置点,以及在清理本地缓存时如何根据访问模式选择 LRU 或 MRU。
这是一则面向 Vibe Coding 工作流的技能安装速记,核心对象是 GitHub 仓库 sickn33/antigravity-awesome-skills 及其可通过 npx skills add 引入的 Antigravity Skills。正文给出四条直接可执行的安装命令,分别添加 rag-engineer、prompt-engineer、langgraph 和 langfuse,覆盖 RAG 工程、提示词工程、LangGraph 编排与 Langfuse 观测相关能力。除命令外,笔记特别标出 Codex App / Codex CLI 与 Google Antigravity 在 Skills 目录命名上的差异:OpenAI Codex 使用 `.agents/skills`,而 Antigravity 使用 `.agent/skills`。这个区别只差一个复数形式,但会直接影响技能文件放置路径,适合在多工具并用或迁移配置时作为校验点。读者可以从中快速复制安装命令,并避免把 Codex 的官方目录约定误套到 Antigravity 上。内容更适合正在配置 AI 编程代理、管理 Skills 仓库,或需要在 Codex 与 Antigravity 之间区分本地目录结构的开发者。