26 篇
1 个三级分类
三级分类
技术体系化整理、工程实践与开发笔记。
专题分组
1 个三级分类
三级分类
2 个三级分类
3 个三级分类
2 个三级分类
2 个三级分类
3 个三级分类
1 个三级分类
三级分类
这是一份面向 VPS 或云服务器场景的 Debian 12 重装速记,核心做法是在当前系统中使用 root 用户下载 bin456789/reinstall 项目的 reinstall.sh 脚本,并通过脚本触发 dd/重装流程。正文给出的主流程包括先用 curl 或 wget 从 GitHub 获取 reinstall.sh,再执行 bash reinstall.sh debian 12 指定安装 Debian 12,完成安装后重启服务器。重启进入新系统后,需要运行 apt-get update -y,并安装 curl、sudo、git 等基础工具,为后续管理、脚本下载和权限操作补齐环境。文章还区分了国外服务器和国内服务器的脚本下载地址:国外可使用 raw.githubusercontent.com,国内则提供 cnb.cool 镜像地址,以降低网络访问 GitHub 失败的概率。需要注意的是,这类重装操作通常会覆盖原系统环境,正文没有展开数据备份、磁盘分区、登录凭据和救援模式等风险处理,因此更适合作为已有经验用户的命令备忘,而不是完整的新手教程。读者可以从中快速确认 Debian 12 重装的最小命令序列,以及在不同网络环境下选择脚本源的方式。
这份笔记给出了一段面向火山引擎 Ark 服务的 Nginx 反向代理配置,用本地 8010 端口承接 `/doubao/` 路径请求,并转发到 `ark.cn-beijing.volces.com:443`。配置的核心目标是降低代理链路中的连接建立和首包等待成本:通过 `upstream` 与 `keepalive 256` 保留上游空闲长连接,配合 `proxy_http_version 1.1` 和清空 `Connection` 头避免请求后立即关闭连接。它还关闭 `proxy_buffering`、开启 `tcp_nodelay`,让响应数据尽快透传给客户端,适合对流式输出或 TTFB 敏感的 AI 接口调用场景。TLS 部分强制使用 TLS 1.3、开启会话复用,并配置 SNI 与上游 Host,确保到 Ark 域名的 HTTPS 握手和路由能够正常工作。文中同时给出 `proxy_socket_keepalive`、真实 IP 透传以及 300 秒读写超时等参数,用于减少空闲连接被中间设备切断、长时间生成过程中断的问题。需要注意的是,配置中为了追求速度关闭了上游证书校验,这会削弱 HTTPS 身份验证安全性,只适合在明确可信的转发链路和可接受风险的场景下使用。整体上,它更像是一份针对 AI 服务反代的低延迟配置清单,适合需要用 Nginx 统一入口、隐藏上游地址或优化接口访问稳定性的后端与运维读者参考。
这是一篇面向 Kubernetes/k3s 日志查看场景的 stern 使用笔记,聚焦在需要同时观察多个 Pod 日志、并在滚动重启后保持日志连续性的日常排查需求。正文先给出 Linux 环境下从 GitHub release 下载 stern 1.33.1、解压、赋权、移动到 /usr/local/bin 并用 stern --version 验证安装的完整命令。随后说明 stern 与 kubectl 一样默认读取本机 K8s 配置,因此在 k3s 环境中可以通过 --kubeconfig /etc/rancher/k3s/k3s.yaml 临时指定配置,也可以把 KUBECONFIG 写入 ~/.bashrc 让后续命令永久生效。示例以 ragapi 为匹配对象,展示 stern ragapi --tail 20/50 这类命令如何聚合查看相关 Pod 的最近日志。文章还强调 stern 相比普通 kubectl logs 的两个实用差异:它会用不同颜色区分不同 Pod,便于定位报错来源;在 rollout restart 后也能自动发现新 Pod 并接续日志流,减少重复执行命令的麻烦。最后补充了按正则包含 error、exception 以及用 -v 排除 GET /health 等噪声日志的过滤方式,适合运维、后端开发或使用 k3s 部署服务的开发者快速整理多实例日志排查流程。
 容器与云原生
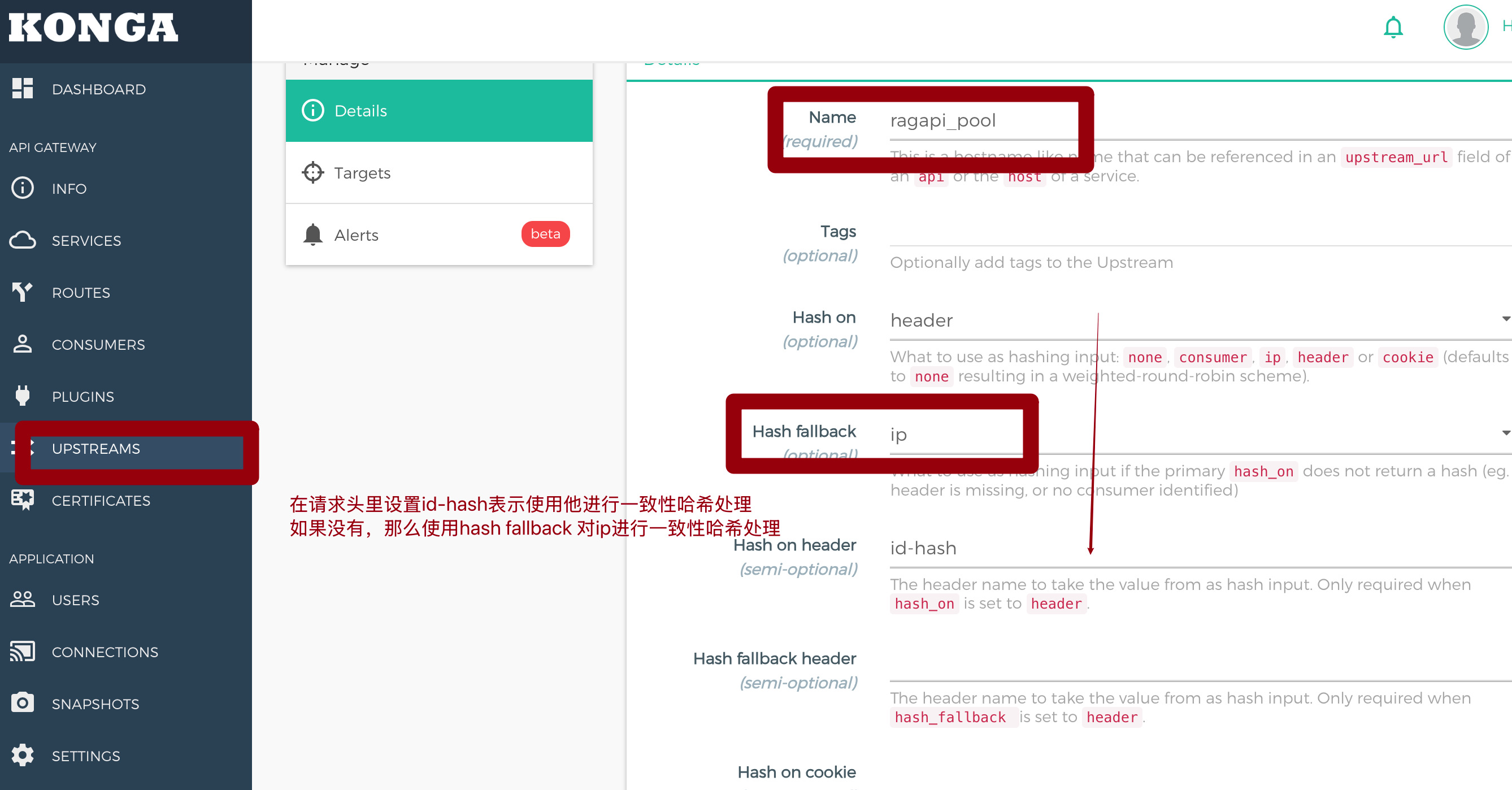
容器与云原生这篇笔记聚焦用 Kong Upstream 为 Kubernetes 中的后端副本做流量分发,场景是 3 个 Pod 暴露在 10.42.0.20 到 10.42.0.22,并通过 Target 与 Service 组合交给 Kong 选择实际后端。内容先区分 Round Robin、Least Connections 与 Consistent Hashing:无状态标准 API 适合轮询,耗时较长的 RAG 向量计算更适合最小连接数,而带本地缓存、用户 Session 或上下文依赖的服务则需要哈希分流来保持请求落点稳定。配置层面强调 Upstream 模式与直连模式的差异,Service Host 指向 upstream 名称后,Service Port 即使写 80 也不会决定最终端口,Kong 会根据上游 Target 中的地址与端口转发到具体的 10.42.0.x:8006。文章还用取余哈希和一致性哈希对比解释扩缩容影响:简单取模在节点数量变化时会导致大量请求重新分布,而 Kong 的一致性哈希通过环形空间顺时针查找,只让新增或减少节点附近的一小段流量发生漂移。对于依赖缓存命中率的 RAG 服务,这种机制能降低扩容、缩容或 Pod 变更时的缓存失效范围,避免瞬时流量冲击。最后对 Target 的 weight 做了关键澄清:在一致性哈希下它更像虚拟节点数量,权重越高,在哈希环上的“分身”和覆盖范围越多,从而获得更大比例的请求,适合需要按 Pod 能力差异分配流量的后端服务。
这是一份在 Kubernetes 中部署 Kong 网关的配置笔记,重点放在 hostNetwork 模式下如何同时兼顾网关性能、本机 PostgreSQL 连接和外部访问安全。配置先用 Secret 保存 pg_password,再通过 Job 执行 kong migrations bootstrap 初始化数据库,随后在 Deployment 中设置 KONG_DATABASE、KONG_PG_HOST、KONG_PG_USER、KONG_PG_DATABASE 等环境变量,让 Kong 直接连接宿主机 127.0.0.1:5432 上的 postgres 数据库。网关容器启用 hostNetwork 并配合 ClusterFirstWithHostNet,代理端口只开放 0.0.0.0:8000,而 Admin API 和 Admin GUI 分别限制在 127.0.0.1:8001 与 127.0.0.1:1337,避免管理端口被公网直接访问。由于 Kong UI 默认没有账号体系,文章给出 Nginx 反代方案,通过 auth_basic 和 .htpasswd 为 kong-ui 域名增加访问保护,并将 /manager-api/ 转发到本地 8001,根路径转发到本地 1337,其中 proxy_pass 末尾斜杠被特别标注为关键细节。另一组 Nginx 配置用于 api 域名,将外部 HTTPS 请求转发到本地 8000 的 Kong Proxy,同时保留真实 IP、WebSocket Upgrade、关闭代理缓冲和上传大小设置。适合需要在单机或混合 Docker/K8s 环境中部署 Kong、使用本机数据库并通过 Nginx 统一暴露 UI 与 API 的后端和运维读者参考。
这篇笔记围绕 FastAPI/Uvicorn 服务在 Kubernetes 中的并发扩展方式,区分了 Pod 副本和 Uvicorn Workers 的层级差异:前者是由 K8s 管理的容器级横向扩展,后者是在单容器内由 Python/Uvicorn 管理的进程级纵向扩展。正文强调二者本质上都会启动独立 Python 进程,因此无论是单 Pod 多 Worker,还是多 Pod 单 Worker,都可以绕开 GIL 对单解释器线程并行的限制,实现多核并行。差异主要落在资源隔离、负载均衡和故障边界上:多 Worker 会共享同一个容器的 CPU 与内存限制,由 Uvicorn 主进程分发请求;多 Pod 则由 K8s Service 做网络层负载均衡,并可为每个 Pod 设置独立资源配额。单 Pod 多 Worker 的优势是启动快、内存更省、进程切换开销较小,但在 2 核 CPU 开 4 个 Worker 这类配置下会发生资源争抢,容器 OOM 时所有 Worker 会一起退出。多 Pod 单 Worker 的优势是每个进程拥有更明确的资源保障,单个 Pod 死锁或内存泄漏只损失部分服务能力,并可由 K8s 自动重启,适合追求稳定性、容灾和大规模水平扩展的部署。读者可以据此判断在成本、启动速度、资源利用率与故障隔离之间如何取舍,而不是简单把副本数和 Worker 数视为等价参数。
“容器与云原生”类别用于归纳与容器化、云原生体系及相关工程实践有关的内容,并为后续文章归类提供一致的判断依据。该类别的重点不只是收纳零散技术笔记,而是明确它适合承载哪些主题、解决哪些分类场景,以及与站内既有类别之间应如何区分。其准则需要说明使用该类别的理由、覆盖范围、典型话题边界,并判断是否存在与其他分类或子分类合并的可能。读者可以据此理解该分类的定位:它面向需要查找容器、平台化、部署运行和云原生相关知识的技术内容,同时强调分类边界的清晰性,避免相近主题被重复放置或分散管理。
 容器与云原生
容器与云原生这份笔记围绕在单机环境中用 k3s 搭建 Kubernetes 并部署实际项目展开,先从 /root/k8s/config.yaml 的基础配置入手,记录了设置 token、tls-san、API 端口、kubeconfig 权限、禁用默认 Traefik 以及把数据目录固定到 /root/k8s/data 的安装方式。可视化管理部分使用 Portainer 官方 manifest 部署到 portainer 命名空间,通过 NodePort 暴露 9000 与 9443,并提醒 Portainer 需要 HTTPS 访问、首次初始化超时后可删除 Pod 触发重建。文章随后给出 Nginx 反向代理到本机 30779 端口的配置示例,包括 SSL、WebSocket 升级头、真实 IP 传递、关闭代理缓冲和上传大小限制。项目部署部分强调用 YAML 与环境文件管理应用,而不是依赖 UI 表单,示例中通过 kubectl create secret generic 从 ragapi.env 创建 Secret,再在 Deployment 中用 envFrom 注入环境变量,并配置私有镜像拉取、RollingUpdate 滚动更新和 Service 的 NodePort 暴露。文中还用类比区分 ConfigMap 与 Secret、Deployment 与 Service:前者分别承载非敏感配置和敏感信息,后者分别负责 Pod 生命周期与流量入口,解释了为什么更新 Pod 时 Service 的地址和端口可以保持稳定。最后整理了一组从 Docker 使用习惯迁移到 kubectl 的常用命令,覆盖查看 Pod/Service/Deployment、跟踪日志、查看资源占用、进入容器,以及通过 rollout restart 或删除 Pod 实现重启,适合刚把个人项目迁移到 k3s 的后端开发者和运维学习者参考。
 容器与云原生
容器与云原生这是一篇面向 Docker 使用者的 Kubernetes 入门笔记,核心在于把 K8s 理解为负责管理和调度容器的编排系统,而不是 Docker 的替代品:Docker 负责打包和运行,K8s 通过声明式期望状态维持副本、自愈、伸缩和资源抽象。文章用对照表梳理 Namespace、Pod、Deployment、StatefulSet、Service、Ingress、ConfigMap/Secret、PV/PVC 等常见对象,并解释 Pod 是 K8s 的最小调度单位,同一 Pod 内容器共享 IP、localhost 通信和存储卷,因此端口不能冲突。重点说明 Pod 具有一次性生命周期,重建后 IP 会变化,所以需要 Service 作为稳定访问入口,并依赖 DNS 将服务名导向当前可用的后端 Pod。Namespace 用于隔离开发、测试、生产等环境,Ingress 则作为七层反向代理处理域名、路径和 HTTPS,相比 NodePort 更适合对外暴露 Web 服务。存储部分通过 PV 与 PVC 区分真实存储资源和使用申请,说明它如何让 Pod 跨节点漂移时仍能挂载到持久化数据。文章最后区分 Deployment 管理无状态应用、StatefulSet 管理数据库等有状态应用,并提醒滚动更新只保证新请求入口平滑切换,长连接仍会在宽限期结束或旧 Pod 退出时断开,需要应用处理 SIGTERM 和客户端重连。
 AI 大模型开发
AI 大模型开发这篇操作笔记围绕在 Attu 中创建 Milvus Collection 展开,把 RAG 知识库建表时容易混在一起的字段设计、索引配置和检索参数拆开说明。正文先以 FloatVector(1024)、VarChar text 和 JSON metadata 为核心字段,解释向量维度必须与 Embedding 模型输出一致,原文文本用于最终回填给 LLM,元数据则服务于按文档、时间等条件做标量过滤。检索部分重点说明 COSINE 余弦相似度适合文本语义搜索,并区分相似度越大越相关、距离或 radius 越小越严格的参数含义,避免在 Milvus 查询时误解阈值方向。索引配置选择 HNSW,并解释 M=16 与 efConstruction=128 分别影响邻居连接数、内存占用、构建速度和查询准确率。文章还对比 Collection 与 Partition 的层级关系:前者类似表并定义统一 Schema,后者是在集合内按业务或时间切分数据,用于缩小搜索范围和控制内存加载。最后补充 Bounded 一致性在写入可见性与吞吐之间折中,以及 Dense、Sparse 和 Hybrid Search 如何把语义检索与关键词权重结合起来提升召回,适合正在搭建 Milvus RAG 数据库的开发者参考。