 容器与云原生
容器与云原生5 分钟
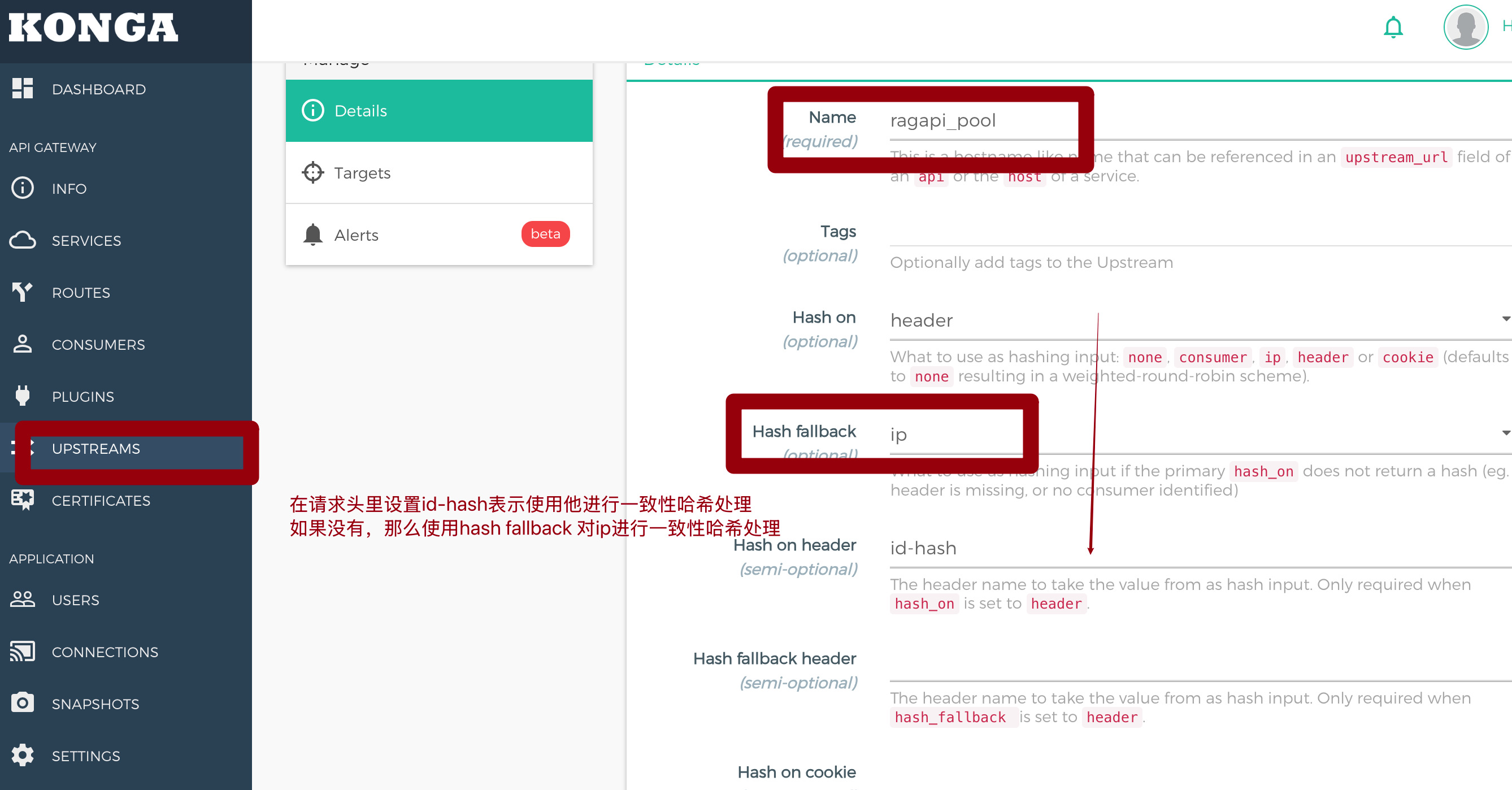
利用 kong 进行流量负载均衡处理
这篇笔记聚焦用 Kong Upstream 为 Kubernetes 中的后端副本做流量分发,场景是 3 个 Pod 暴露在 10.42.0.20 到 10.42.0.22,并通过 Target 与 Service 组合交给 Kong 选择实际后端。内容先区分 Round Robin、Least Connections 与 Consistent Hashing:无状态标准 API 适合轮询,耗时较长的 RAG 向量计算更适合最小连接数,而带本地缓存、用户 Session 或上下文依赖的服务则需要哈希分流来保持请求落点稳定。配置层面强调 Upstream 模式与直连模式的差异,Service Host 指向 upstream 名称后,Service Port 即使写 80 也不会决定最终端口,Kong 会根据上游 Target 中的地址与端口转发到具体的 10.42.0.x:8006。文章还用取余哈希和一致性哈希对比解释扩缩容影响:简单取模在节点数量变化时会导致大量请求重新分布,而 Kong 的一致性哈希通过环形空间顺时针查找,只让新增或减少节点附近的一小段流量发生漂移。对于依赖缓存命中率的 RAG 服务,这种机制能降低扩容、缩容或 Pod 变更时的缓存失效范围,避免瞬时流量冲击。最后对 Target 的 weight 做了关键澄清:在一致性哈希下它更像虚拟节点数量,权重越高,在哈希环上的“分身”和覆盖范围越多,从而获得更大比例的请求,适合需要按 Pod 能力差异分配流量的后端服务。



